Introduction to distributions and basic sampling in CUQIpy#
This notebook describes basic usage of distributions in CUQIpy including visualizing their probability density function (PDF) and cumulative distribution function (CDF), and generating samples. Then conditional distributions are demonstrated along with the creation of user-defined distributions.
Learning objectives of this notebook:#
Going through this notebook, you will see how to:
Set up random variables following univariate and multivariate distributions in CUQIpy.
Generate samples from distributions and use CUQIpy tools to inspect visually.
Set up conditional distributions in CUQIpy - simple and using lambda functions.
★ Create a user-defined distribution from a logpdf function.
Table of contents:#
★ Indicates optional section.
References#
[1] Bardsley, Johnathan. 2018. Computational Uncertainty Quantification for Inverse Problems. SIAM, Society for Industrial and Applied Mathematics.
First we need to import any Python packages needed, here NumPy for array computations and Matplotlib for plotting.
import numpy as np
import matplotlib.pyplot as plt
We import CUQIpy. In the other notebooks we may import upfront the specific tools we need, like from cuqi.distribution import Gaussian to get the Gaussian distribution from CUQIpy’s distribution module. We now simply import the complete package and then specify the complete name such as cuqi.distribution.Gaussian when using it. Both approaches are fine, each with pros and cons.
import cuqi
1. Normal distribution (univariate) #
The first thing we can do is to define a simple normal distribution of a single variable, e.g.,
This is done using the following syntax:
x = cuqi.distribution.Normal(mean=0, std=1)
More information on the distribution can be found in the CUQIpy API documentation.
Once created, we can print the distribution object, and its dimension and name:
print(x)
print(x.dim)
print(x.name)
CUQI Normal.
1
x
Note about the distribution name:
The distribution name is inferred automatically from the assignment statement
x = cuqi.distribution.Normal(mean=0, std=1).Since the distribution was assigned to the variable
x, by default, the distribution name will bex.One can specify a different name by explicitly passing the
nameargument, e.g.x = cuqi.distribution.Normal(mean=0, std=1, name='x1').
We can query other information about this distribution such as its mean and standard deviation:
print(x.mean)
print(x.std)
0
1
Distributions in CUQIpy have commonly used methods that one might expect like pdf, logpdf, cdf, etc. For example we can evaluate the CDF at 0, which should be 0.5, since the pdf is symmetric about 0:
x.cdf(0)
0.5
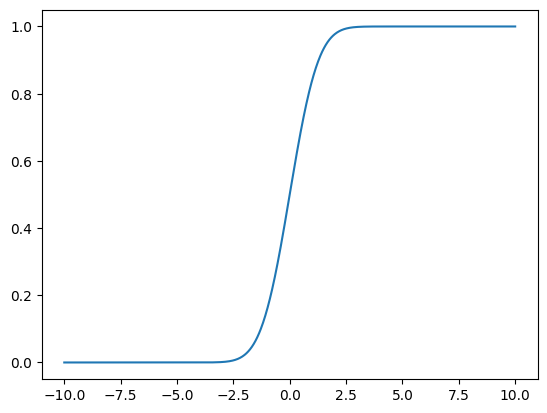
We can evaluate and plot the CDF on an interval by evaluating the CDF on a grid:
grid = np.linspace(-10, 10, 1001)
cdf_vals = np.zeros(grid.shape)
for k in range(len(grid)):
cdf_vals[k] = x.cdf(grid[k])
plt.plot(grid, cdf_vals)
[<matplotlib.lines.Line2D at 0x7ff8ad0de080>]
Alternative more compact form using python’s list comprehension:
plt.plot(grid, [x.cdf(node_k) for node_k in grid])
[<matplotlib.lines.Line2D at 0x7ff8aafe3160>]
CUQIpy distributions also have sample method which returns one or more samples from the distribution as a CUQIarray:
x.sample()
CUQIarray: NumPy array wrapped with geometry.
---------------------------------------------
Geometry:
_DefaultGeometry1D(1,)
Parameters:
True
Array:
CUQIarray(-0.54086146)
By default a single sample is returned. More samples can easily be requested:
x_samples = x.sample(10000)
type(x_samples)
cuqi.samples._samples.Samples
When more than one sample is generated, a CUQIpy Samples object is returned. This is essentially an array in which each column contains one sample, and further equipped with a number of methods for computing samples statistics, diagnostics and plotting.
We can look at all the plotting methods available for the Samples object:
# A list of all plotting methods
[method for method in dir(x_samples) if method.startswith('plot')]
['plot',
'plot_autocorrelation',
'plot_chain',
'plot_ci',
'plot_ci_width',
'plot_mean',
'plot_median',
'plot_pair',
'plot_std',
'plot_trace',
'plot_variance',
'plot_violin']
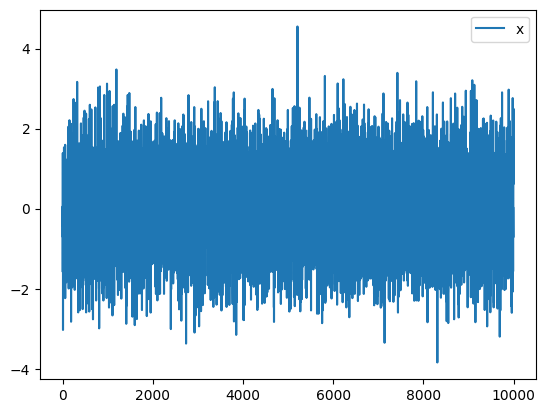
For example, one can make a “chain plot”, i.e., the sampled values of selected parameter(s) of interest. Here we have a single parameter and with Python being zero-indexed, we specify this parameter, the 0-th element of x, as follows:
x_samples.plot_chain(0)
[<matplotlib.lines.Line2D at 0x7ff8ab06e500>]
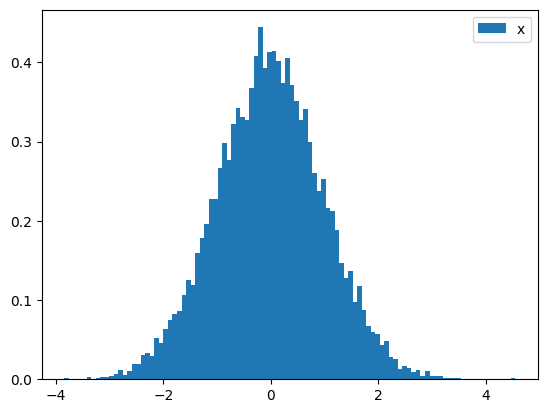
Another possibility is a histogram of the parameter chain: (The keyword arguments are passed directly to the underlying matplotlib hist function for full control). Again, we specify 0 as the element to look at the chain for:
x_samples.hist_chain(0, bins=100, density=True)
<BarContainer object of 100 artists>
CUQIpy has integrated support for common statistical plots with the ArviZ library, for example a “trace plot” combines the previous two plots, where the histogram is replaced by a kernel density estimate (KDE).
x_samples.plot_trace()
array([[<Axes: title={'center': 'x'}>, <Axes: title={'center': 'x'}>]],
dtype=object)

Try yourself (optional):#
Create a new random variable
rfollowing a normal distribution with mean 2 and standard deviation 3.Generate 100 samples and display a histogram.
Compare with the theoretical distribution by plotting the probability density function of
ron top of the histogram.Increase the number of samples and (hopefully) see the histogram approach the theoretical PDF.
# Type code here:
2. Multivariate distributions #
CUQIpy currently implements a number of multivariate distributions in the cuqi.distribution module:
[dist for dist in dir(cuqi.distribution) if not dist.startswith('_')]
['Beta',
'CMRF',
'Cauchy',
'Distribution',
'DistributionGallery',
'GMRF',
'Gamma',
'Gaussian',
'InverseGamma',
'JointDistribution',
'JointGaussianSqrtPrec',
'LMRF',
'Laplace',
'Lognormal',
'ModifiedHalfNormal',
'MultipleLikelihoodPosterior',
'Normal',
'Posterior',
'SmoothedLaplace',
'Uniform',
'UserDefinedDistribution']
and more can easily be added when needed.
As a demonstration, we specify here a 4-element random variable y following a Gaussian distribution with independent elements:
true_mu = np.array([5, 3, 1, 0])
true_sigma = np.array([1, 2, 3, 0.5])
y = cuqi.distribution.Gaussian(mean=true_mu, cov=true_sigma**2)
As before, we can take a look at the distribution by printing it and its dimension:
print(y)
print(y.dim)
print(y.name)
CUQI Gaussian.
4
y
as well as its mean
print(y.mean)
[5 3 1 0]
and its diagonal covariance matrix (represented as a 1D array of the diagonal values):
print(y.cov)
[1. 4. 9. 0.25]
We generate a single sample, which is represented by a 4-element CUQIarray:
y.sample()
CUQIarray: NumPy array wrapped with geometry.
---------------------------------------------
Geometry:
_DefaultGeometry1D(4,)
Parameters:
True
Array:
CUQIarray([ 7.0762582 , 0.98687145, -1.1600899 , 0.15338883])
If we ask for more than one sample, say 1000, we get a Samples object with 1000 columns each holding a 4-element sample:
y_samples = y.sample(1000)
print(y_samples)
CUQIpy Samples:
---------------
Ns (number of samples):
1000
Geometry:
_DefaultGeometry1D(4,)
Shape:
(4, 1000)
Samples:
[[ 4.78966232 5.54257023 5.57279575 ... 4.73430686 5.39530042
4.36136563]
[ 4.29049341 2.79373017 3.41643221 ... 1.81266541 2.79546802
4.26857654]
[ 3.31162542 -1.01787506 -4.68632431 ... -2.58518826 1.93209344
-3.70475253]
[ 0.30970553 0.19750224 0.2458065 ... -0.06308874 -0.21205153
-0.12329265]]
We can plot chains of a few of these variable samples, here we pick element 2 and 0:
y_samples.plot_chain([2, 0])
[<matplotlib.lines.Line2D at 0x7ff8aabd8bb0>,
<matplotlib.lines.Line2D at 0x7ff8aabd8ca0>]
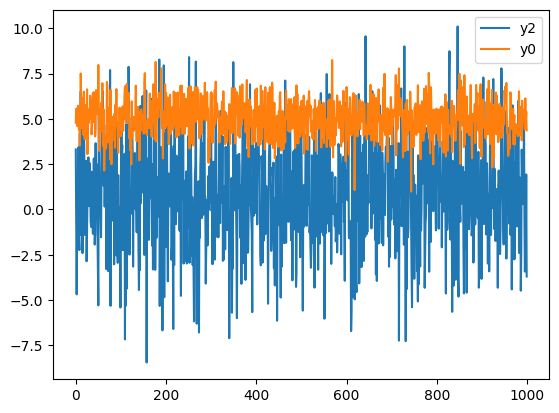
We can as well plot a few samples of y, each containing 4 elements:
y_samples.plot(marker='o');
Plotting 5 randomly selected samples
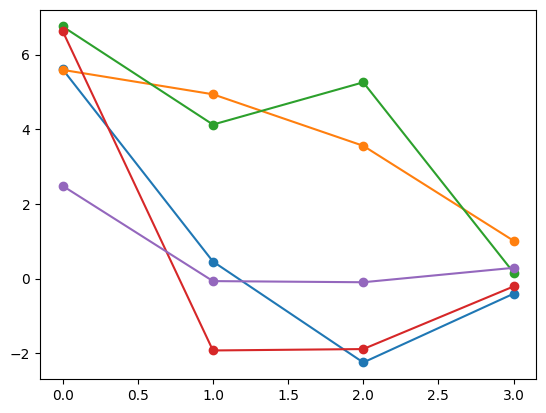
By default 5 random samples are plotted, but we can also specify indices of specific samples we wish to plot, like the 1st and 3rd samples:
y_samples.plot([1, 3], marker='o');
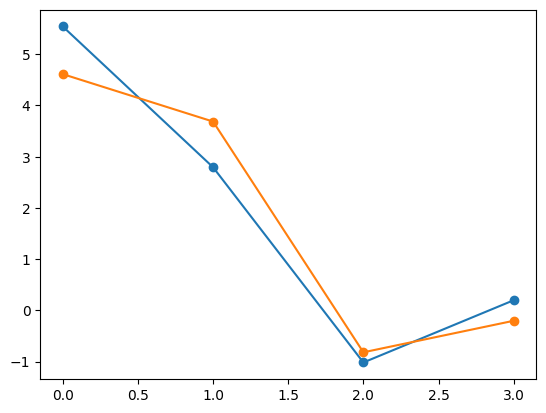
Another option for inspecting samples is a “violin plot”, which displays the median as a white circle, the interquartile range, along with the density/histogram on either side:
y_samples.plot_violin()
array([<Axes: title={'center': 'y0'}>, <Axes: title={'center': 'y1'}>,
<Axes: title={'center': 'y2'}>, <Axes: title={'center': 'y3'}>],
dtype=object)

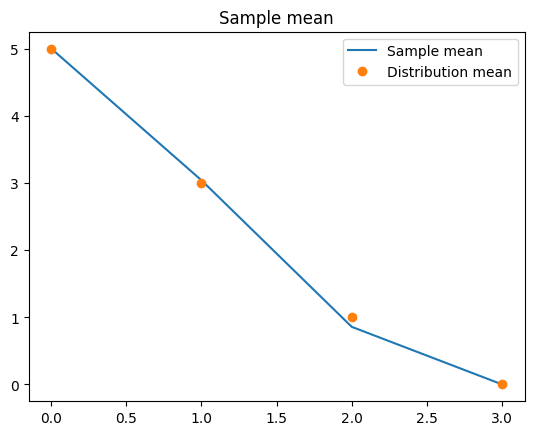
We can also plot the sample mean and compare with the true mean of the distribution:
y_samples.plot_mean(label="Sample mean")
plt.plot(y.mean, 'o', label="Distribution mean")
plt.legend()
<matplotlib.legend.Legend at 0x7ff8aaa4b850>
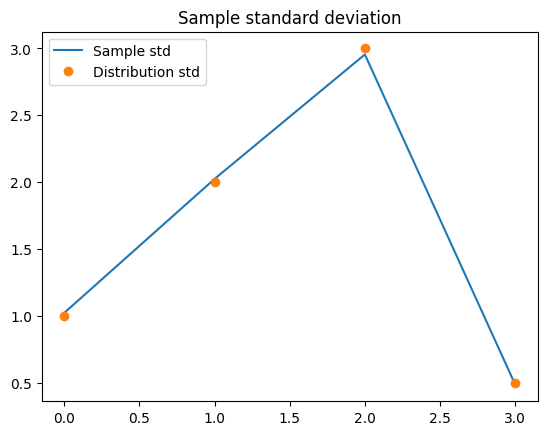
and sample standard deviation along with the true standard deviations of the distribution which we obtain as the square-root of the diagonal of the covariance matrix:
y_samples.plot_std(label="Sample std")
plt.plot(np.sqrt(y.cov), 'o', label="Distribution std")
plt.legend()
<matplotlib.legend.Legend at 0x7ff8aab02fb0>
Try yourself (optional):#
Plot mean with 95% credibility interval, hint:
help(y_samples.plot_ci).When plotting credibility interval with
plot_ci, plot also the true mean using theexactkeyword argument.Reduce and increase the number of samples and study the effect on the mean and credibility interval.
Try also 50% and 99% credibility intervals.
# Type code here:
3. Conditional distributions #
CUQIpy also support conditional probability distributions, which are probability distributions that are defined conditionally on the value of one or more other random variables.
In CUQIpy, defining conditional distributions is simple. Assume we are interested in defining the Normal distribution conditioned on a random variable representing the standard deviation, e.g.
This can simply be achieved by omitting the keyword argument for the standard deviation, when defining the distribution, as shown in the following code
z = cuqi.distribution.Normal(mean=0)
Printing it will tell us that the variable std has not been specified, i.e., it is a conditioning variable:
print(z)
CUQI Normal. Conditioning variables ['std'].
Because \(z\) is a conditional distribution, we cannot evaluate the logpdf or sample it directly without specifying the value of the conditioning variable (the standard deviation in this case). Hence this code will fail to run:
# This code will give an error so we wrap it in a try/except block and print the error
try:
z.sample()
except Exception as e:
print(e)
Cannot sample from conditional distribution. Missing conditioning variables: ['std']
To specify the conditioning variable we use the “call” syntax, i.e., z(std=2) to set the value of the standard deviation in the conditional distribution as shown below.
z(std=2).sample()
CUQIarray: NumPy array wrapped with geometry.
---------------------------------------------
Geometry:
_DefaultGeometry1D(1,)
Parameters:
True
Array:
CUQIarray(2.51485824)
In fact, conditioning creates a new unconditional distribution. Here printing reveals that it does not have any conditioning variables:
z_given_std = z(std=2)
print(z_given_std)
CUQI Normal.
We expect we can then sample it directly, which is confirmed:
z_given_std.sample()
CUQIarray: NumPy array wrapped with geometry.
---------------------------------------------
Geometry:
_DefaultGeometry1D(1,)
Parameters:
True
Array:
CUQIarray(0.72223276)
In general, one may need more flexibility than simply conditioning directly on the attributes of the distribution. Let us assume we want to define a distribution that is conditional on the variance - denoted \(d\) - rather than the standard deviation of the normal distribution, i.e.
In CUQIpy this can be achieved through lambda functions. A lambda function is the Python equivalent of a MATLAB anonymous function, i.e. a function defined in a single line with the following syntax for an example function the simply sums two input arguments:
myfun = lambda v1, v2: v1+v2
myfun(5,7)
12
We can pass a lambda function directly as an argument to a CUQIpy distribution, e.g.,
w = cuqi.distribution.Normal(mean=0, std=lambda d: np.sqrt(d))
print(w)
CUQI Normal. Conditioning variables ['d'].
where we see that d is now the conditioning variable instead of std as before.
We can then pass a value for d to condition on, which allows us to sample from the now fully specified distribution:
w(d=2).sample()
CUQIarray: NumPy array wrapped with geometry.
---------------------------------------------
Geometry:
_DefaultGeometry1D(1,)
Parameters:
True
Array:
CUQIarray(2.55806848)
What actually happens behind the scenes is that writing w(d=2) defined a new CUQIpy distribution where the standard deviation is set by evaluating the lambda function. This can be seen by storing the new distribution as follows.
w_given_d = w(d=2)
w_given_d.std
1.4142135623730951
This framework allows for a lot of flexibility in defining conditional distributions. For example we can define lambda functions for all attributes (here the mean and the standard deviation):
#Functions for mean and std with various (shared) inputs
mean = lambda sigma, gamma: sigma+gamma
std = lambda delta, gamma: np.sqrt(delta+gamma)
u = cuqi.distribution.Normal(mean, std)
print(u)
CUQI Normal. Conditioning variables ['sigma', 'gamma', 'delta'].
The three variable names sigma, gamma and delta used to define the two lambda functions for the mean and standard deviation are now the conditioning variables of the conditional distribution u.
By providing values for all three variables we obtain a fully specified distribution
u_given_all = u(sigma=3, delta=5, gamma=-2)
print(u_given_all)
CUQI Normal.
that we can sample:
u_given_all.sample()
CUQIarray: NumPy array wrapped with geometry.
---------------------------------------------
Geometry:
_DefaultGeometry1D(1,)
Parameters:
True
Array:
CUQIarray(1.31690793)
Conditional distributions play a major role when specifying Bayesian inverse problems in CUQIpy and in particular those problems that include Bayesian hierarchical models where some random variables depend on other random variables. We revisit this in later notebooks.
4. User-defined distributions ★ #
In addition to the distributions provided by CUQIpy, there is also the possibility for users to specify new distributions. One option is to write their own class in the same style as existing distributions such as the Cauchy distribution (see code here: Cauchy).
Another option is to specify a user-defined distribution, which is convenient if one, for example, only wishes to evaluate the logpdf.
The example below demonstrates how to manually specify a normal distribution through a lambda function for the logpdf and compare it to the normal distribution defined in the beginning of this notebook.
We specify variables for the mean and the standard deviation and specify the lambda function for the logpdf.
mu1 = 0
std1 = 1
logpdf_func = lambda xx: -np.log(std1*np.sqrt(2*np.pi))-0.5*((xx-mu1)/std1)**2
To set up the user-defined distribution, we need to specify the logpdf as well as its dimension (number of variables) since that cannot be automatically inferred from the lambda function:
x_user = cuqi.distribution.UserDefinedDistribution(dim=1, logpdf_func=logpdf_func)
We can now evalute the logpdf, as well as the pdf:
print(x_user.logpdf(0))
print(x_user.pdf(0))
-0.9189385332046727
0.3989422804014327
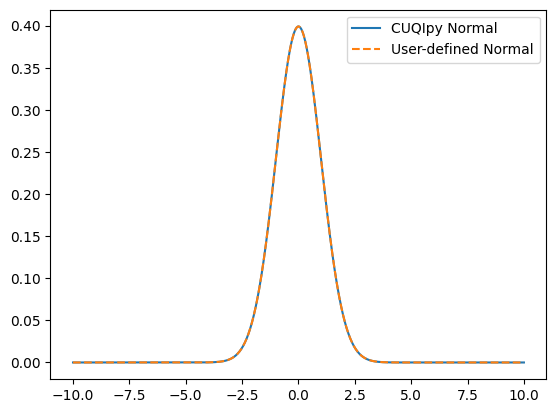
We can compare this with the normal distribution from the beginning of the notebook and observe that their pdfs agree:
plt.plot(grid, [x.pdf(node_k) for node_k in grid], label='CUQIpy Normal')
plt.plot(grid, [x_user.pdf(node_k) for node_k in grid], '--', label='User-defined Normal')
plt.legend()
<matplotlib.legend.Legend at 0x7ff8aac93df0>
We cannot sample the user-defined distribution because we have only provided the logpdf:
try:
x_user.sample()
except Exception as e:
print(e)
sample_func is not defined. Sampling can be performed by passing the density to a sampler from the 'sampler' module.
We can equip the user-defined distribution with a sample_func which specified how to sample (it is up to the user to ensure consistency between logpdf and sample_func):
x_user.sample_func = lambda : np.array(mu1 + std1*np.random.randn())
x_user.sample()
CUQIarray: NumPy array wrapped with geometry.
---------------------------------------------
Geometry:
_DefaultGeometry1D(1,)
Parameters:
True
Array:
CUQIarray(1.90728303)
We can compare the samples obtained from the original normal distribution and the user-defined:
x_samples = x.sample(10000)
x_user_samples = x_user.sample(10000)
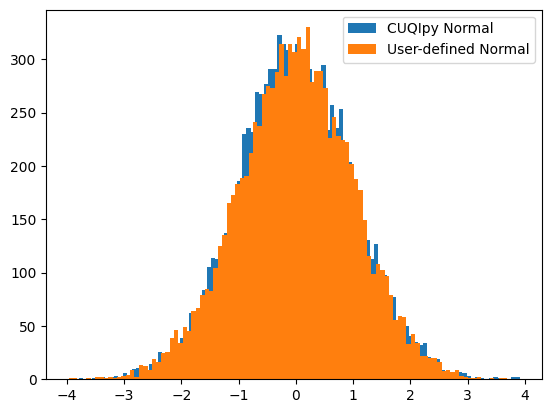
We plot their histograms and note that they appear similar:
x_samples.hist_chain(0,bins=100)
x_user_samples.hist_chain(0,bins=100)
plt.legend(['CUQIpy Normal', 'User-defined Normal'])
<matplotlib.legend.Legend at 0x7ff8ad135150>