In some Bayesian inverse problems, the posterior for is known in closed analytical form. However, it may not always be practical to work with: for high-dimensional distributions or when the forward model is computationally expensive, it is a computational challenge to compute posterior moments. Moreover, in most Bayesian inverse problems the posterior is not known in analytical form. Hence, there is a need for a different way to access the posterior.
A density function provides a mathematical description of the behavior of a random variable. If we produce many outcomes - or samples - of the random variable following the posterior , then these samples help us estimate where most samples are concentrated and how they are spread out, corresponding to high and low density regions of the probability density function, respectively.
And even in those cases where we have closed form expression for the posterior, its use may require large computational efforts, e.g., to determine posterior moments via numerical quadrature.
This leads to the important concept of sampling in uncertainty quantification. This is a key technique that involves generating many possible outcomes of following the posterior , thus allowing us to build a statistical “picture” of its uncertainty via estimates of variance, covariance, etc. There are many approaches and methods for sampling, and several of them are available in CUQIpy and described in later chapters. For more details, see, e.g., Calvetti & Somersalo (2023, Ch. 4). Below, we illustrate the concept of sampling with a few simple examples.
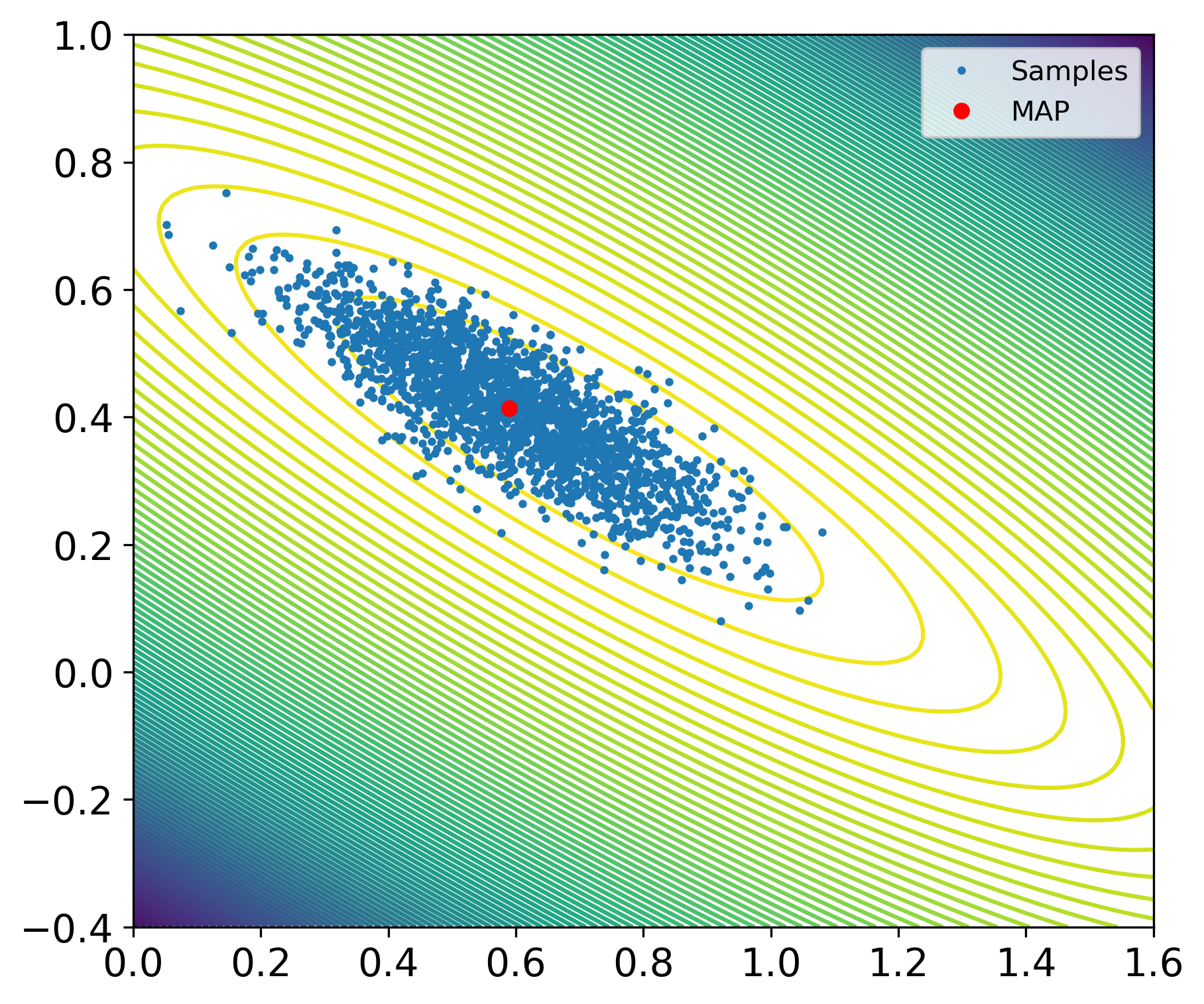
Example 4: Sampling the Gaussian likelihood in the linear regression problem. We return to the problem from Example 3 with Gaussian noise and a Gaussian prior, giving a Gaussian posterior. It is instructive to present an example where we can compare samples of the posterior against its analytic density function. This is shown in the figure below, where the dots are the samples and the background are contour plots of the posterior. Indeed, we see that the density of samples is higher near the least squares estimate and, overall, follows the Gaussian shape.
Example 5. Sampling the non-Gaussian posterior in the falling object problem. We now demonstrate the use of sampling for a Bayesian inverse problem where there is no simple analytical expression for the posterior. We use the test problem from Example 2 with the same Gaussian noise and the same parameters, and with two different priors. We compute 50,000 samples of the posterior using the Metropolis-Hasting sampling method - see 1. Sampling with CUQIpy: five little stories for a discussion of this sampling method.
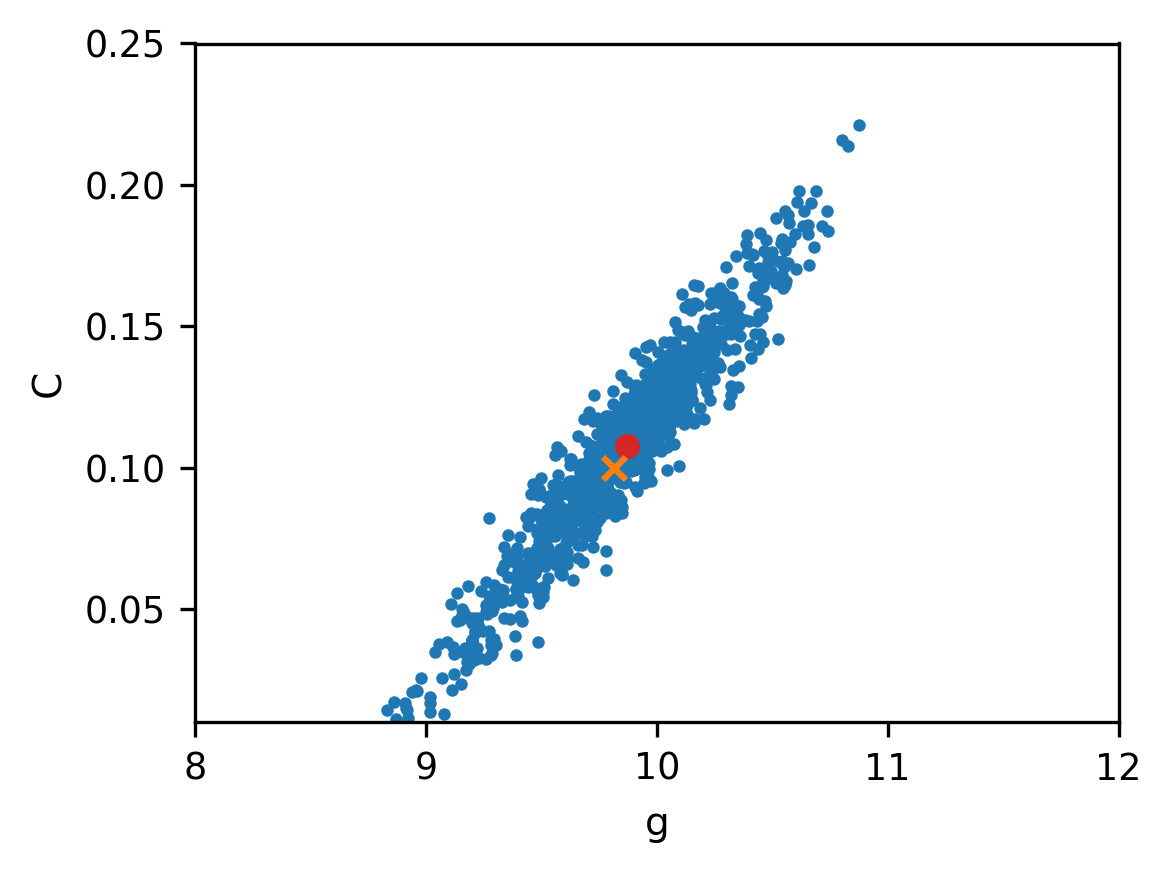
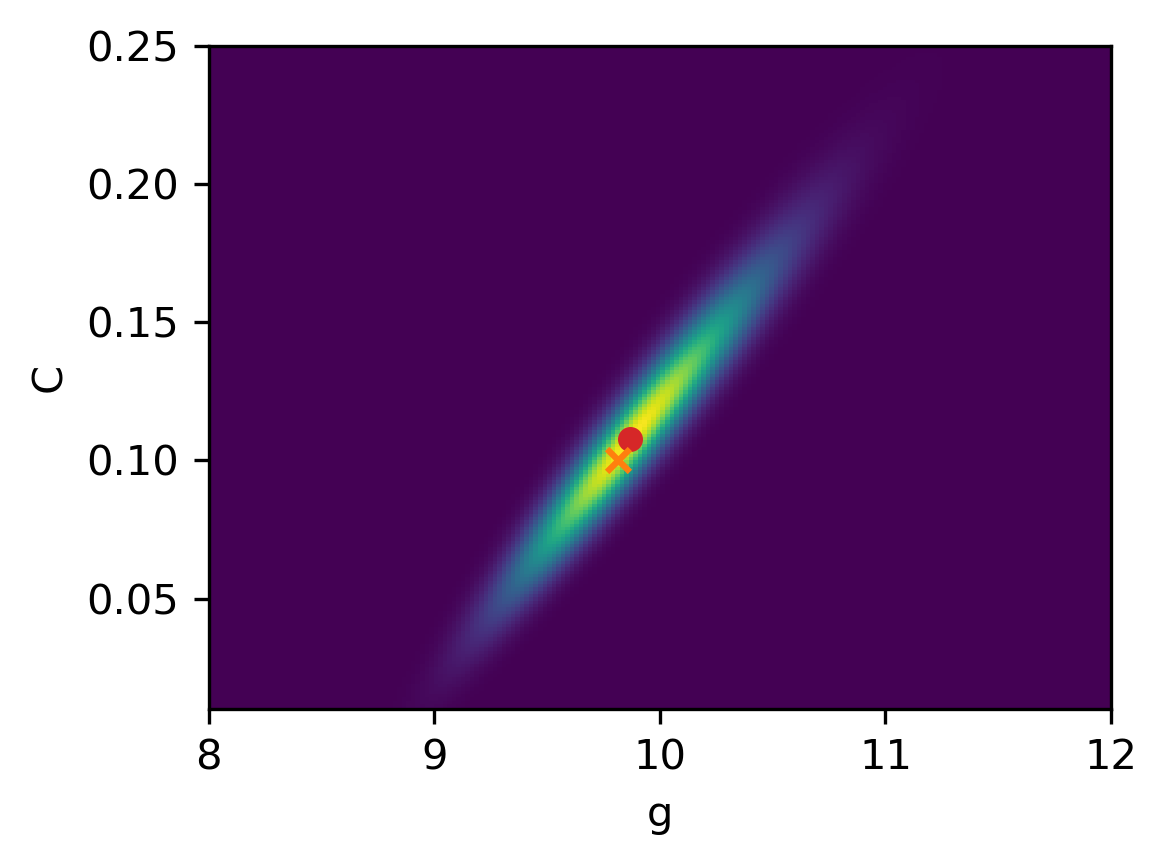
The first prior was suggested in Allmaras et al. (2013), and we assume that and are uniformly distributed in the intervals and , respectively. The main role of this prior is to ensure positive estimates, which are allowed to take values in wide intervals. The two figures below show the samples and the posterior; the red dot indicates the MAP estimates and . Clearly, the estimates for and are correlated as evidenced by the tilt of the posterior.
The second prior in this example takes the form of a truncated Gaussian distribution for and given by with mean, covariance matrix, and lower and upper bounds
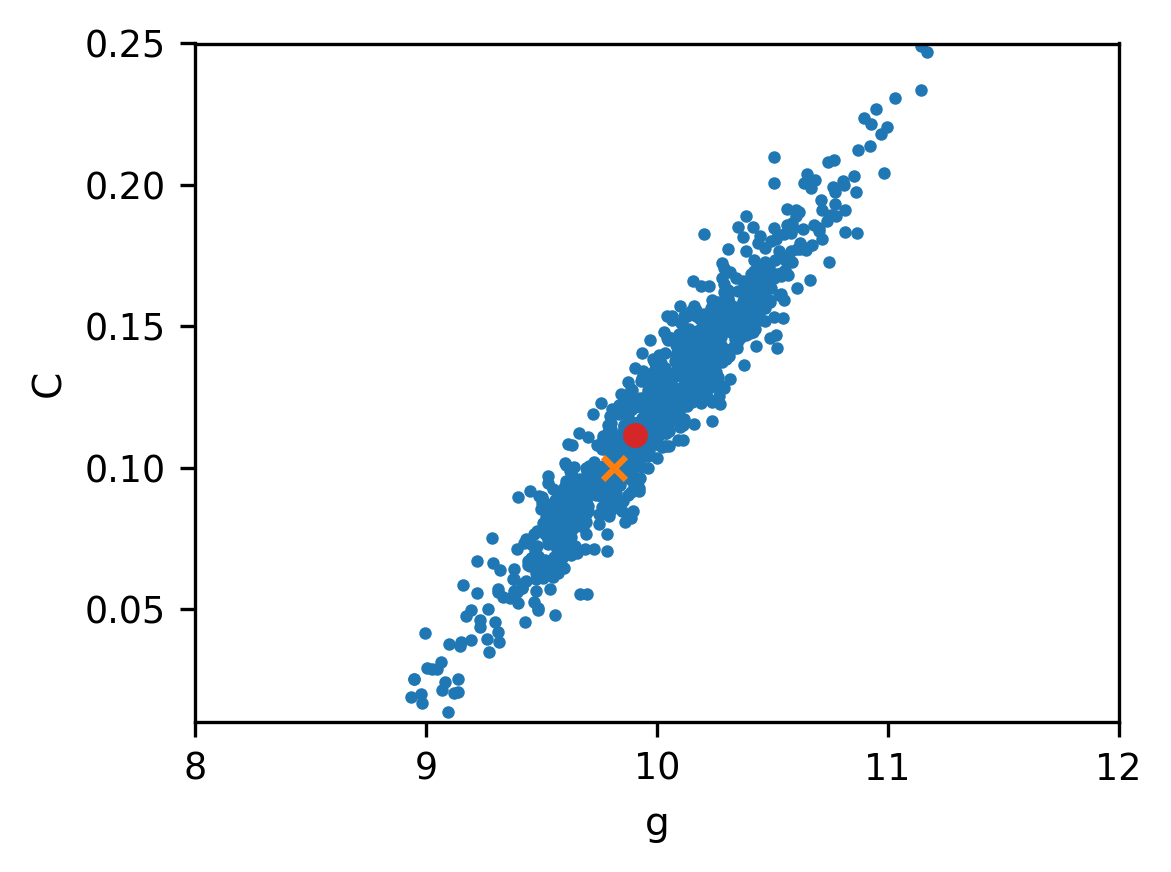
The two values of the mean for this prior are very different from the values and used to synthetically generate the data. Moreover, the covariance matrix is chosen to have large variance and thus allowing the estimates to take values in a large range. The samples and the posterior are shown in the figure below, where the red dot indicates the MAP estimates and and the orange cross indicates the ground truth and .
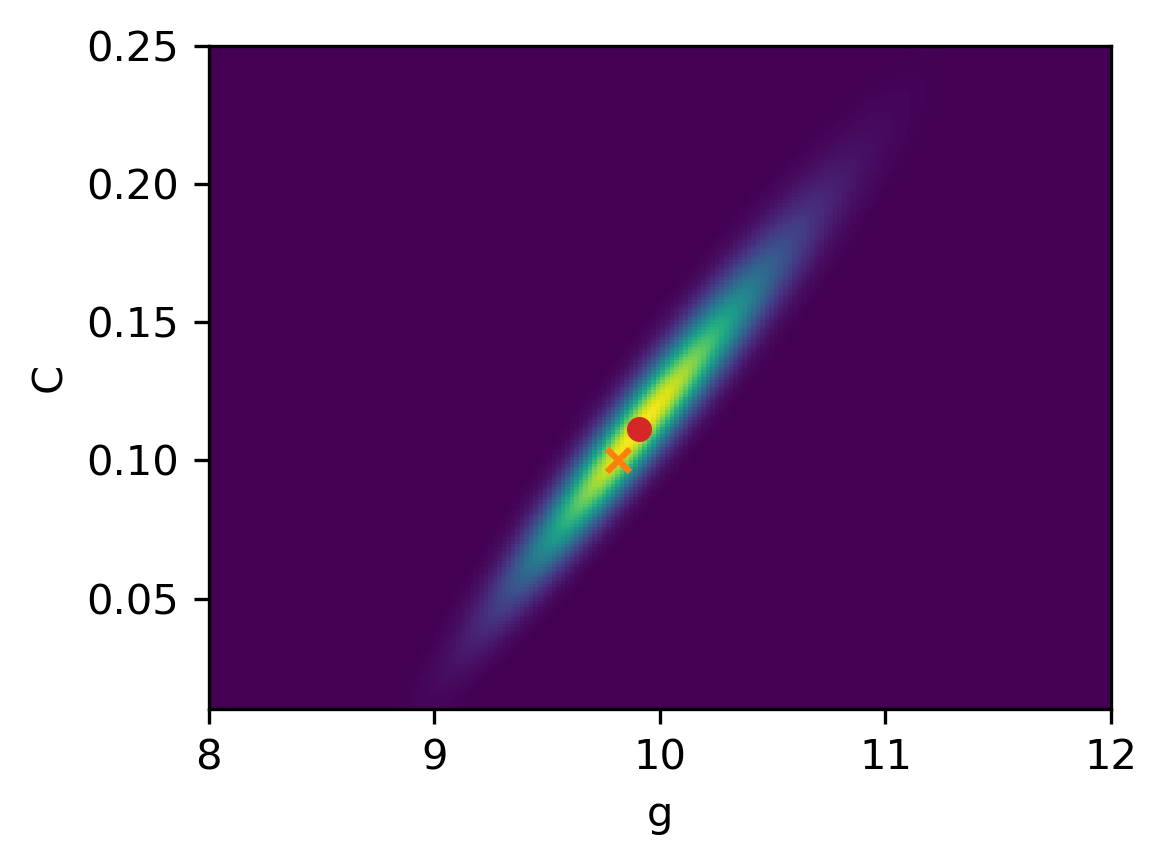
These two priors, that allow a wide range of values of the estimates, give rise to posteriors that are primarily determined by the likelihood. Therefore, the mean of the prior - whose values are far from the parameters used in the data simulation - plays only a minor role and hence both priors give results that are quite similar with good estimates.
We finish with an example that clearly illustrates the role played by the prior. If we believe that our chosen mean reflects the true values of the parameters and , then we should choose a covariance matrix with small variance. This gives a “strong prior” that puts a lot of emphasis on the mean because the posterior is now dominated by the prior. This is all good if the mean if well chosen - but it can also be dangerous if we have too much confidence in a bad prior that does not reflect reality.
Example 6. Sampling with a bad prior. We return to the example with the falling object with a truncated Gaussian distribution for the prior, and we use the same mean as in the previous example. But this time we use a covariance matrix with much smaller variance
which expresses a strong belief in the mean. The samples and the posterior are shown in the figures below.
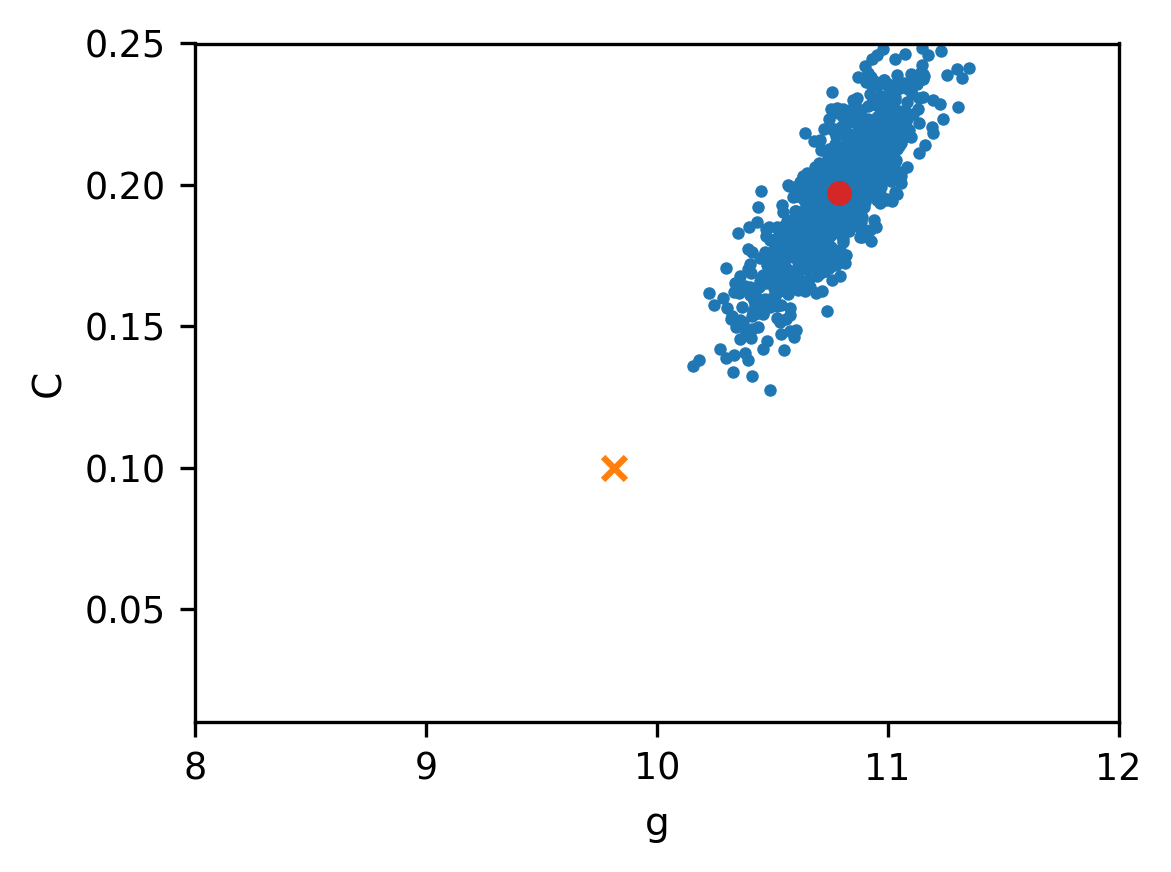
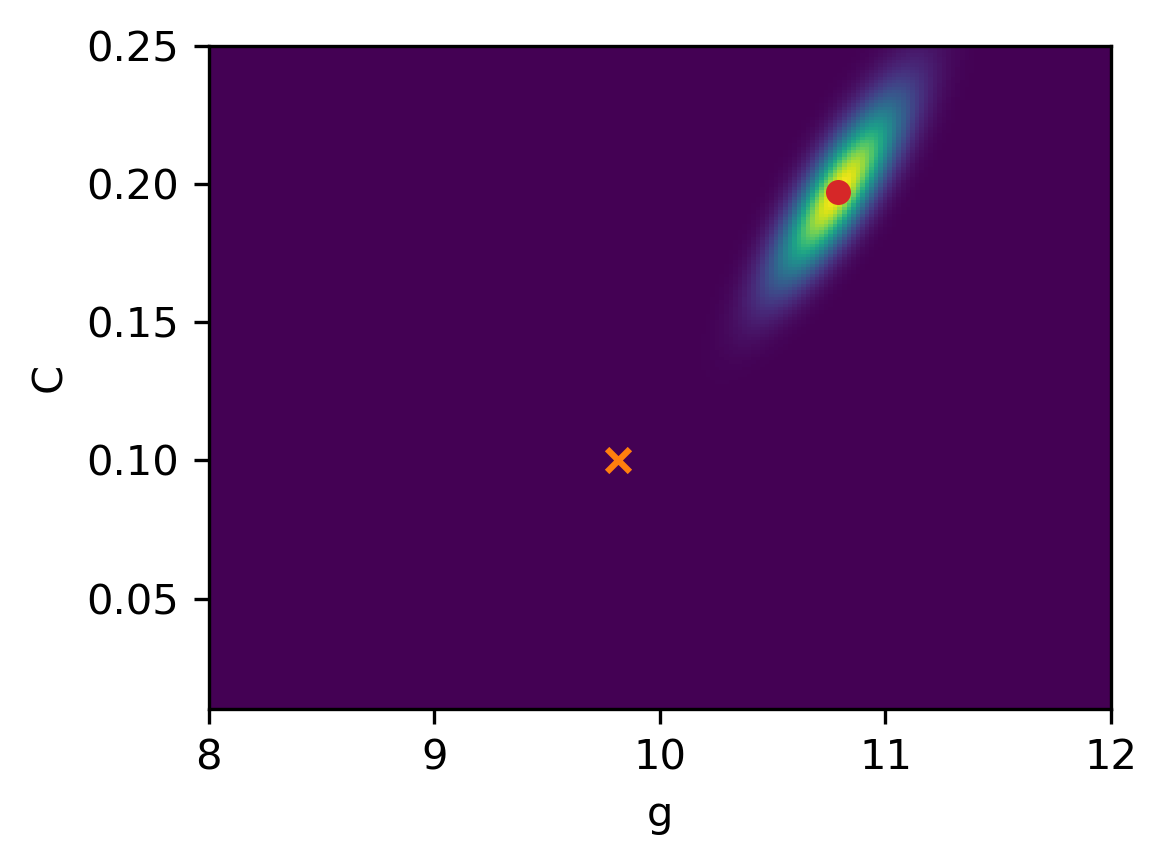
The MAP estimates are and . This posterior is more concentrated due to the strong prior - but due to the bad choice of the mean the estimates are far from the actual values.
This concludes the introduction to computational uncertainty quantification for inverse problems.
- Calvetti, D., & Somersalo, E. (2023). Bayesian Scientific Computing (Vol. 215). Springer.
- Allmaras, M., Bangerth, W., Linhart, J. M., Polanco, J., Wang, F., Wang, K., Webster, J., & Zedler, S. (2013). Estimating parameters in physical models through Bayesian inversion: A complete example. SIAM Review, 55(1), 149–167.