For pedagogical reasons it instructive to consider the special case where both the likelihood and the prior are Gaussian. Moreover, this choice is also commonly used in practice. Assuming again a linear forward model and noisy data with iid Gaussian noise, the likelihood function is given by (8). For an iid Gaussian prior, in dimensions the prior is given exactly by
Omitting the normalization constant (which does not depend on ) yields the common shorthand
This prior expresses that the elements of are independent and follow a Gaussian distribution with zero mean and standard deviation that controls the concentration of the prior around the mean (which is zero here). The smaller is, the tighter the density is around the mean, meaning the prior favors values of close to zero; conversely, the larger is, the more spread out the prior is, suggesting that could take a wider range of values with higher probability.
Hence, the posterior is a product of two Gaussian functions and therefore it is also Gaussian with a closed-form expression (except for the normalization constant):
The corresponding covariance matrix for this Gaussian distribution is
We immediately notice a resemblance with Tikhonov regularization mentioned above. Specifically, the maximum a posterior (MAP) estimate of - the one what maximizes the posterior in (14) - is the one that minimizes the negative argument of the exponential function. This optimization problem is identical to the Tikhonov problem in (7) if we set (see, e.g. Bardsley (2018, sec. 4.1)). Here we immediately recognize an advantage of the Bayesian formulation because it provides an explicit expression for the parameter .
It is often necessary to extend the simple Gaussian prior in (12) to a prior of the form
where is the prior mean and is a suitably chosen matrix that is used to tailor the prior to our needs. For example, we can impose smoothness (or regularity) of by choosing as a discretization to a derivative operator; see Bardsley (2018, sec. 4.2) for details.
Example 3: Linear regression with a Gaussian prior. To illustrate the role of the prior, we return to the linear regression problem from Example 1 for which the two least squares estimates are quite correlated and having large uncertainties. We choose a Gaussian prior (12) with . Then the MAP estimate and the covariance matrix are
The figure below shows the posterior with a less elongated ellipse than the Gaussian for the least squares problem. The red dot represents the MAP estimate.
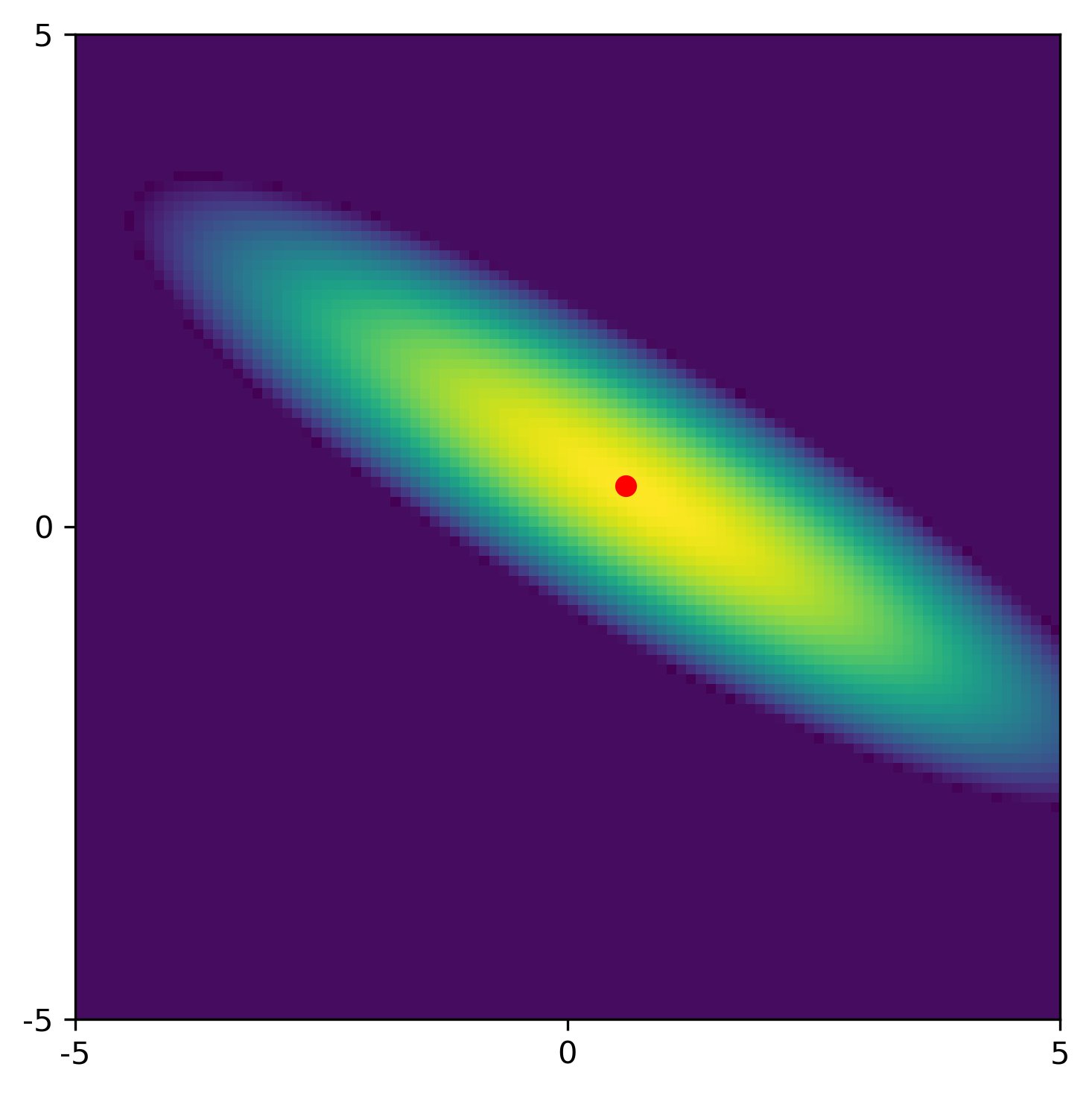
Compared to the least squares results without using a prior, 1) we obtain better estimates, 2) we reduce the correlation between the estimates, and 3) we reduce the standard deviations of the estimates.
The above example illustrates how casting the estimation problem in the Bayesian framework gives us more control of the solution than if we use classical least squares estimation.
- Bardsley, J. M. (2018). Computational Uncertainty Quantification for Inverse Problems. SIAM.