We consider a Bayesian inverse problem in which we infer a conductivity field from potential measurements everywhere in a 1D domain, similar problem in a 2D domain was presented in 2. PDE-based BIP using CUQIpy and CUQIpy-FEniCS plugin. The forward map from the conductivity to the measurements is governed by the 1D Poisson equation with zero Neumann boundary condition at the left and Dirichlet boundary condition at the right, and source term :
where we use a log parameterization, , to ensure positivity of the inferred conductivity. We denote by and the discretized versions of the log conductivity field and the potential, respectively, and we denote by the forward map , which for a given returns the measurements of the potential everywhere in the domain.
In this section, we present two Bayesian inverse problem setups for this problem. Both setups share the same forward model and likelihood, and differ only in the choice of the prior for the log conductivity field :
In the first setup, we use a GMRF prior
and in the second setup, we use a TV-type implicit prior
We compare the results obtained from these two setups to illustrate the effect of the choice of the prior on the posterior distribution and the inferred conductivity field.
Table of Contents¶
2.1. Learning objectives
2.2. Setting up a CUQIpy PDE object and the forward model
2.3. BIP setup with GMRF prior
2.4. BIP setup with TV-type implicit prior
2.1. Learning objectives ¶
Describe the MYULA algorithm and how it is different from ULA.
Describe how Moreau-Yosida smoothing is used to overcome the non-differentiability of the TV prior in the MYULA algorithm.
Write the MYULA step in terms of the proximal operator of the TV prior.
Create
RestorationPriorandMoreauYoshidaPriorobjects in CUQIpy to create a TV-type implicit prior.Sample from the posterior distribution using the MYULA algorithm and analyze the results.
This notebook is under the GPLv3.0 license.
This notebook was run on a machine locally and not using github actions for this book. To run this notebook on your machine, you need to have CUQIpy-FEniCS installed.
We import the necessary libraries and modules.
from cuqi.distribution import Gaussian, GMRF, JointDistribution
from cuqi.implicitprior import RestorationPrior, MoreauYoshidaPrior
from cuqi.sampler import ULA
from cuqi.model import PDEModel
from cuqi.array import CUQIarray
from cuqi.geometry import Continuous1D
from cuqipy_fenics.geometry import FEniCSContinuous
from cuqipy_fenics.pde import SteadyStateLinearFEniCSPDE
import numpy as np
import dolfin as dl
import matplotlib.pyplot as plt
from skimage.restoration import denoise_tv_chambolle
import ufl
# Set logging level of dl
dl.set_log_level(dl.LogLevel.ERROR)2.2. Setting up a CUQIpy PDE object and the forward model¶
In this section, we set up a CUQIpy PDE object for the 1D Poisson problem described above and define the forward model. We assume the reader is familiar with the basics of FEniCS and finite element methods. However, understanding the details of this section is not required to follow the rest of the notebook, namely, sections 2.3 and 2.4.
First we create a mesh and define a function space for the PDE problem using FEniCS dolfin library.
n = 80 # number of nodes in the mesh
mesh = dl.IntervalMesh(n-1, 0, 1)
# Function space for the solution u
solution_function_space = dl.FunctionSpace(mesh, 'Lagrange', 1)
# Function space for the parameter m
parameter_function_space = dl.FunctionSpace(mesh, 'Lagrange', 1)We then define the FEniCS variational form for the 1D poission problem.
source_signal = 10 # source term in the PDE
def form(m,u,p):
return ufl.exp(m)*ufl.inner(ufl.grad(u), ufl.grad(p))*ufl.dx\
- dl.Constant(source_signal)*p*ufl.dxWe define the Dirichlet boundary condition for the PDE problem as well as the corresponding adjoint Dirichlet boundary condition which is needed for the gradient-based sampling methods ULA and MYULA that we will use later in this notebook.
def u_boundary(x, on_boundary):
return on_boundary and ((x[0] > 1-dl.DOLFIN_EPS))
dirichlet_bc_expression = dl.Expression("right_bc*(x[0]>endpoint-eps)",
eps=dl.DOLFIN_EPS, endpoint=1,
right_bc=1, degree=1)
dirichlet_bc = [dl.DirichletBC(
solution_function_space, dirichlet_bc_expression, u_boundary)]
adjoint_dirichlet_bc = [dl.DirichletBC(
solution_function_space, dl.Constant(0), u_boundary)]After that we create CUQIpy-FEniCS PDE object, to which we supply the form, the function spaces, and the boundary conditions.
PDE = SteadyStateLinearFEniCSPDE(
form, mesh, solution_function_space, parameter_function_space,
dirichlet_bc, adjoint_dirichlet_bc)Then we create the CUQIpy forward model to which we supply the PDE object, and the domain and the range geometries.
domain_geometry = FEniCSContinuous(parameter_function_space)
range_geometry = FEniCSContinuous(solution_function_space)
F = PDEModel(PDE,range_geometry,domain_geometry)This concludes setting up the forward model F.
2.3. BIP setup with a GMRF prior¶
To infer the log conductivity field, we set up the following Bayesian model
where is the variance of the Gaussian noise in the measurements.
GMRF prior¶
We create a GMRF prior for the log conductivity field as follows
m = GMRF(np.zeros(domain_geometry.par_dim), 25) The true signal¶
We choose a true log conductivity field to be a piecewise constant function given as follows
m_true_array = np.ones(n)*-1
m_true_array[int(n/3):2*int(n/3)] = -0.5
m_true = CUQIarray(m_true_array, geometry=domain_geometry)
m_true.plot()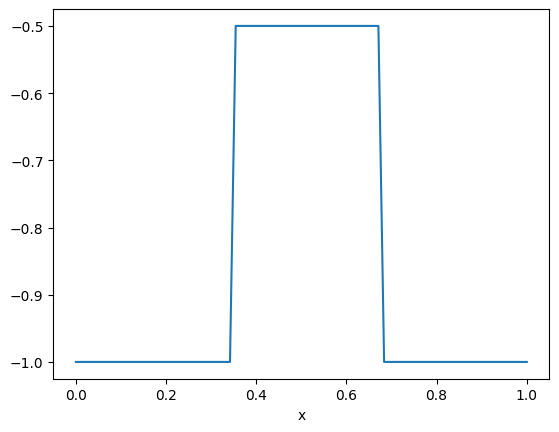
The likelihood, the data, and the posterior distribution¶
We then create the data distribution assuming a noise level noise
noise = 0.02
y = Gaussian(mean=F(m), cov=noise**2*np.eye(range_geometry.par_dim),
geometry=range_geometry)And we generate a realization of the data by sampling from the data distribution at the true log conductivity field.
y_obs = y(m=m_true.parameters).sample()
y_obs.plot(label="observation")
F(m_true).plot(label="exact data")
plt.legend()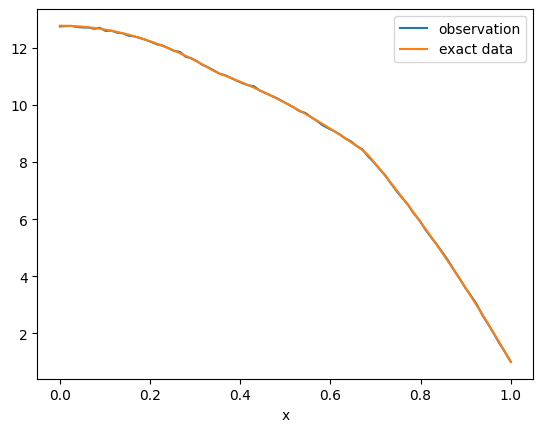
The posterior distribution, given the data , is then given by
where is the likelihood function, i.e. the data distribution PDF at a fixed , and is the prior distribution PDF. The posterior distribution can equivalently be written as
where . We create the posterior distribution in CUQIpy as follows
posterior = JointDistribution(m, y)(y=y_obs)Sampling using ULA¶
In 1. Sampling with CUQIpy: five little stories, we introduce the Unadjusted Langevin Algorithm (ULA) for sampling from the posterior distribution. We recall the ULA update step for sampling from a posterior distribution with PDF as follows
where is the current sample and is the next sample, is the step size, and is a standard Gaussian multi-variate random variable. We sample from the posterior distribution using the CUQIpy implementation of ULA. First, we set the number of samples and the thinning factor:
Ns = 100000
Nt = 100Then we create the ULA sampler and sample from the posterior distribution as follows
initial_point_ula = np.ones(n)*-0.75
delta_ula = 2e-6
sampler_ula = ULA(posterior, initial_point=initial_point_ula, scale=delta_ula)
sampler_ula.sample(Ns, Nt=Nt)
samples_ula = sampler_ula.get_samples()Sample: 100%|██████████| 100000/100000 [1:22:08<00:00, 20.29it/s, acc rate: 100.00%]
We plot the credibility interval for the inferred log conductivity field
# Switch samples geometry to Continuous1D for better plotting of the credibility interval
samples_ula.geometry = Continuous1D(np.flip(mesh.coordinates()[:,0]))
samples_ula.plot_ci(95, exact=m_true)
plt.ylim(-1.4, 0)
plt.xlim(0, 1)(0.0, 1.0)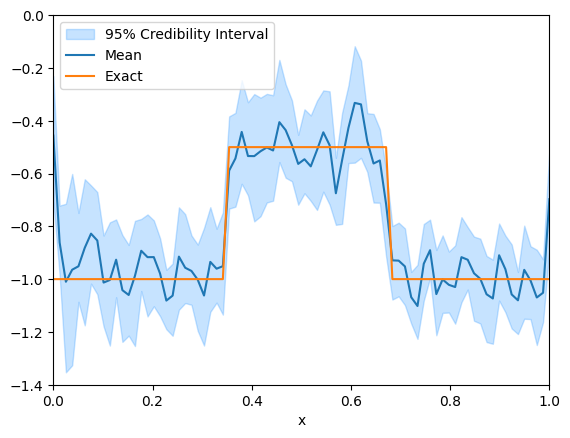
We notice that the credibility interval roughly captures the true solution, but both the credibility interval and the mean are highly oscillatory and do not capture the piecewise constant nature of the true solution. In the next section, we impose a TV-type implicit prior through the MYULA framework to capture the piecewise constant nature of the true solution.
2.4. BIP setup with a TV-type implicit prior¶
Principles behind MYULA sampling method¶
The Moreau-Yosida Unadjusted Langevin Algorithm (MYULA) was introduced in Durmus et al. (2018) as an extension of the ULA algorithm to allow sampling from posterior distributions with non-differentiable priors, such as TV-type priors. The main idea behind MYULA is to use Moreau-Yosida regularization to create a smoothed version of the original non-differentiable prior, which allows us to compute the gradient needed for the Langevin updates.
To take an ULA step, as described above, we need the gradient of the log-posterior which involves the gradient of the log-prior . In the case in which is non-differentiable, we can consider as a surrogate posterior the density where is a smoothed version of the original prior .
In MYULA setting, we obtain the smoothed counterpart of by applying the Moreau envelope as follows
The smoothing strength controls how closely the smoothed prior approximates the original prior , and as it goes to zero, the smoothed prior converges to the original prior. is continuously differentiable and its gradient can be computed as follows Bauschke & Combettes (2017)
where the proximal operator of , , is defined as follows
MYULA step for sampling from the surrogate posterior is then given by
TV-type implicit prior and the Bayesian model setup¶
We want to impose a TV-type implicit prior on the log conductivity field to capture the piecewise constant nature of the true solution. In this case, the negative log prior is given by the 1D non-differentiable TV function of as follows
where is a weight parameter for the TV term. To apply MYULA, we only need the proximal operator of , which is also known as a TV denoising operator. This operator takes a signal as input and returns a more TV-regularized signal and is available in, e.g., scikit-image. In CUQIpy, we use the term “restoration operator” as a general term to refer to denoising operators, as well as other types of operators that can be used to define implicit priors through the MYULA and PnPULA Laumont et al. (2022) frameworks. For brevity, we focus in this section on the MYULA framework, and the reader can refer to Laumont et al. (2022) and Everink et al. (2025) for the PnPULA framework.
The gradient of the smoothed counterpart of is then given by
and multiplying by gives us the gradient of the smoothed counterpart of as follows
using the fact that and defining .
The Bayesian inverse problem setup with the TV-type implicit prior is then given by
where is the normalization constant of the prior distribution which we do not need to compute for sampling from the posterior distribution using MYULA.
To create a TV-type implicit prior in CUQIpy, we use the RestorationPrior and the MoreauYoshidaPrior classes. The RestorationPrior requires as input a restoration operator, which in our case is the TV denoising operator. This operator is provided in the form of a python function that takes a signal and a parameter controlling the strength of restoration restoration_strength, in this case, as input and returns the denoised (restored) signal.
lambda_tv = 200
def restore_TV(x, restoration_strength=None):
# Use scikit-image's TV denoising operator denoise_tv_chambolle
denoised_image = denoise_tv_chambolle(
x, weight=lambda_tv * restoration_strength, max_num_iter=100
)
return denoised_image, NoneThe parameter lambda_tv is the value of , which controls the strength of the TV regularization term relative to the likelihood term in the posterior distribution. The larger the lambda_tv parameter, the stronger the TV regularization term, driving the inferred solution to be closer to a piecewise constant function.
We use the restore_TV function to create the CUQIpy RestorationPrior object as follows
restorator = RestorationPrior(
restore_TV,
geometry=F.domain_geometry
)We then define our smoothed TV prior m_tv as follows
alpha = 100*noise**2
alpha_prime = alpha/lambda_tv
m_tv = MoreauYoshidaPrior(
restorator, smoothing_strength=alpha_prime)The MoreauYoshidaPrior object, m_tv, provides the gradient of .
Now we can create the data distribution and the posterior distribution as follows
y_tv = Gaussian(F(m_tv), noise**2, geometry=F.range_geometry)
posterior_tv = JointDistribution(y_tv, m_tv)(y_tv=y_obs)
Sampling using MYULA in CUQIpy¶
We sample the posterior using the ULA algorithm with the smoothed TV prior, which is in essence the MYULA algorithm, as follows
scale_myula =2e-6
initial_point_myula = np.ones(n)*-0.75
sampler_myula = ULA(
posterior_tv, scale=scale_myula, initial_point=initial_point_myula)
sampler_myula.sample(Ns, Nt=Nt)
samples_myula = sampler_myula.get_samples()Sample: 100%|██████████| 100000/100000 [1:15:57<00:00, 21.94it/s, acc rate: 100.00%]
And we plot the credibility intervals for the MYULA samples
# Switch samples geometry to Continuous1D for better plotting of the credibility interval
samples_myula.geometry = Continuous1D(np.flip(mesh.coordinates()[:,0]))
samples_myula.plot_ci(95, exact=m_true)
plt.ylim(-1.4,0)
plt.xlim(0,1)(0.0, 1.0)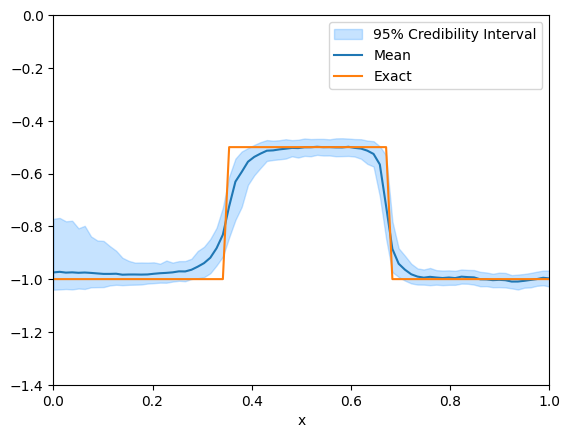
Note that the MYULA samples are much less oscillatory than the ULA samples with GMRF prior, and they capture the piecewise constant nature of the true solution much better.
- Durmus, A., Moulines, E., & Pereyra, M. (2018). Efficient Bayesian computation by proximal Markov chain Monte Carlo: when Langevin meets Moreau. SIAM Journal on Imaging Sciences, 11(1), 473–506.
- Bauschke, H. H., & Combettes, P. L. (2017). Correction to: Convex Analysis and Monotone Operator Theory in Hilbert Spaces. In Convex Analysis and Monotone Operator Theory in Hilbert Spaces (pp. C1–C4). Springer International Publishing. 10.1007/978-3-319-48311-5_31
- Laumont, R., Bortoli, V. D., Almansa, A., Delon, J., Durmus, A., & Pereyra, M. (2022). Bayesian imaging using plug & play priors: when langevin meets tweedie. SIAM Journal on Imaging Sciences, 15(2), 701–737.
- Everink, J. M., Zhang, C., Alghamdi, A., Laumont, R., Riis, N. A., & Jørgensen, J. S. (2025). A Computational Framework and Implementation of Implicit Priors in Bayesian Inverse Problems. arXiv Preprint arXiv:2509.11781. 10.48550/arXiv.2509.11781