Measured data inevitably contain errors, and we must understand how such errors influence the results that we compute. In other words, we want to understand the uncertainties in our results caused by the errors in the data. The CUQIpy package provides computational methods that allow us to do that, and this chapters provides the conceptual background for formulating and performing this uncertainty quantification.
Errors in measured data are unavoidable. They have many causes, such as imperfections in the measurement device and spurious signals that we cannot avoid recording. In this work we consider the errors to be random (as opposed to deterministic or systematic errors), and we often know - or can estimate - their size and their statistical distribution.
Uncertainty is, by definition, “a lack of sureness about something.” In our context it refers to the fact that random data errors inevitably lead to an error in the computed solution, and hence this solution has some degree of uncertainty. It is desirable to characterize this uncertainty; for example, we want to know the size and properties of the uncertainty.
Quantification refers, in this respect, to the act of rigorously determining the amount and type of uncertainty in the solution, given statistical information about the data errors. This is done using well-defined mathematical/statistical methods and tools. Uncertainty quantification implies that we want more details than just, e.g., a bound for the error in the solution.
There are potentially other types of errors than those coming from the measured data. We use a mathematical model to describe the data, and this model may also be influenced by errors e.g., when we neglect second-order terms in complex models or when some model parameters are slightly incorrect. Moreover, our computations are always influenced, to some degree, by floating-point errors on the computer Björck, 2024, sec. 1.4. Neither type of errors can be handled by the CUQIpy software, and we will therefore not discuss them here.
It is instructive to illustrate the uncertainty due to data errors with two simple examples of parameter estimation. The first problem in linear, and we have an explicit formula for the solution’s covariance matrix which helps illustrate basic aspects of uncertainty quantification. The second problem is nonlinear and thus well suited for illustrating how computational uncertainty quantification can be performed in practice when no analytical expressions are available.
Example 1: Linear regression. We are given a linear function
where the two parameters and are unknown. We assume that the noisy data , are given by
and our task is to estimate the two unknown parameters. Since the noise is independent and identically distributed (iid) Gaussian with variance , it is natural to use the method of least squares estimation Björck, 2024Hansen et al., 2013. The least squares estimates and are given by
where and are the averages of and , respectively. The figure below illustrates this for a case with , , and , and the least squares estimates are and .
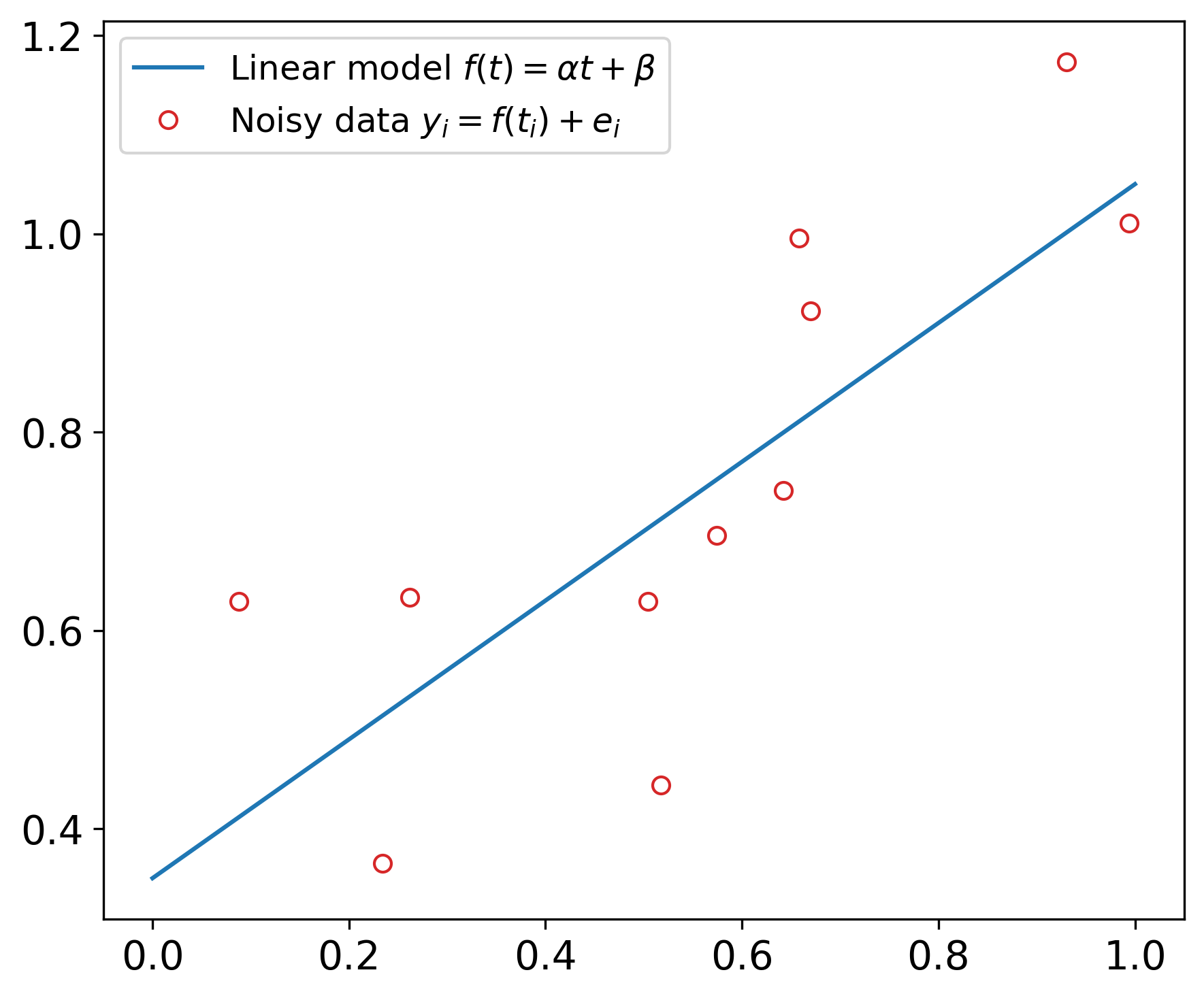
A statistical approach gives insight about the influence of the noise on the estimated parameters. This least squares estimation problem is linear, it follows that the two estimates follow a bivariate Gaussian distribution , whose mean is the vector of the exact parameters. Moreover, the covariance matrix is given by
The 2D Gaussian distribution is illustrated in the figure below, where the red dot represents the least squares solution for this particular noise realization. Note that appears as a factor in ; as the Gaussian approaches a delta distribution.
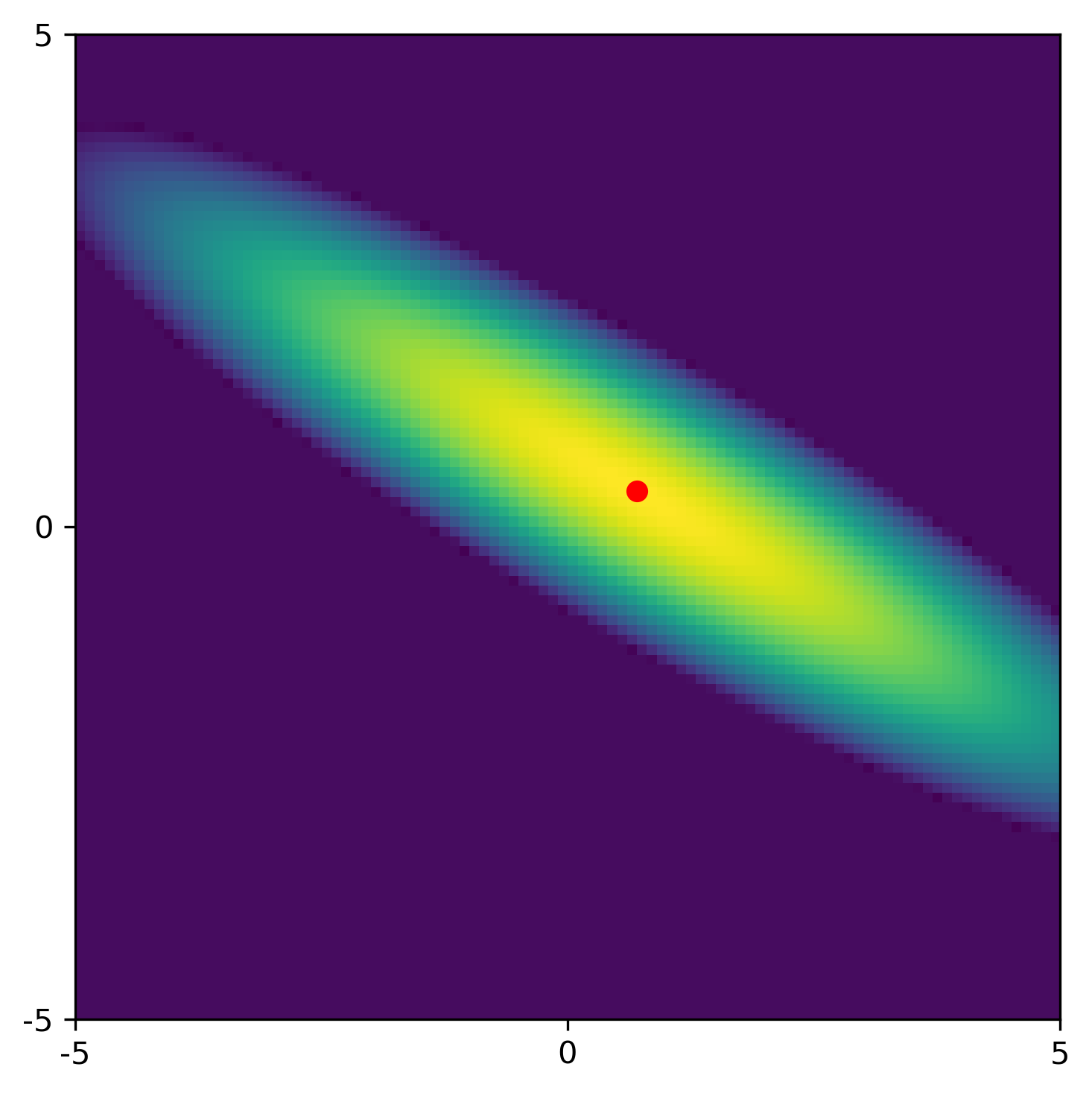
This constitutes the quantification of the uncertainties in the least squares estimates. The nonzero off-diagonal elements of show that there is quite some correlation between the two estimates, revealing itself by the tilt of the ellipsoid in the figure. The standard deviations for and (the square roots of the diagonal elements of ) are 0.22 and 0.11, respectively. These numbers confirm that both parameters are approximated with some uncertainty.
Example 2: A falling object. This example is inspired by a carefully explained case study in Allmaras et al. (2013). From measurements of an object in a free fall in air (which causes a drag on the object), we want to determine the gravitational acceleration and the coefficient of air resistance (or drag) . The dynamics are described by a pair of ordinary differential equations - see Allmaras et al. (2013) for details - and there is an analytical expression for the distance the object has fallen, as a function of time , from a resting position at time :
As expected, this result is independent on the object’s mass.
If we measure this distance at times then we obtain noisy data
We assume Gaussian noise with , and we use the parameters and .
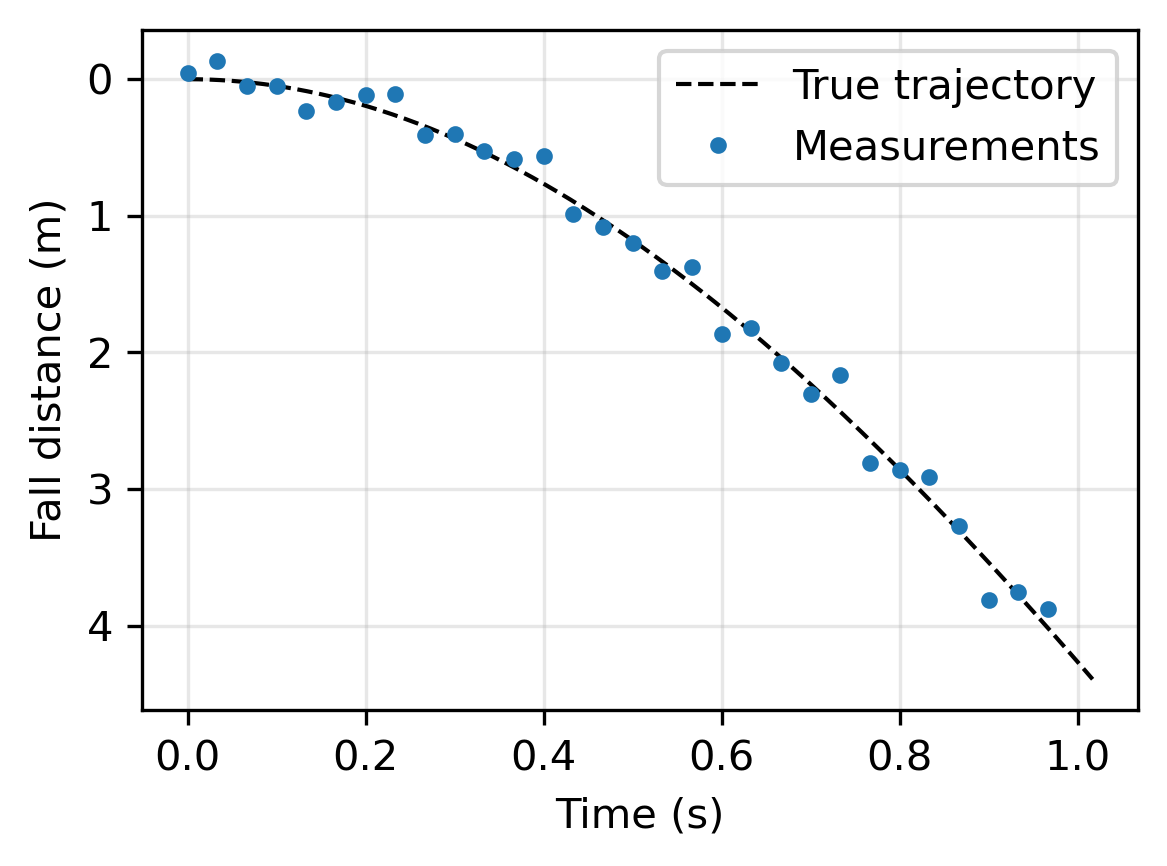
The two parameters and appear nonlinearly in this problem, and hence we use a nonlinear least squares solver to compute the estimates and . Assessing the uncertainties in this nonlinear problem cannot be done via a covariance matrix (as in the first example), and in 5. Computational UQ: the need for sampling we demonstrate how this is done by computational uncertainty quantification and CUQIpy.
- Björck, Å. (2024). Numerical Methods for Least Squares Problems. SIAM.
- Hansen, P. C., Pereyra, V., & Scherer, G. (2013). Least Squares Data Fitting with Applications. JHU Press.
- Allmaras, M., Bangerth, W., Linhart, J. M., Polanco, J., Wang, F., Wang, K., Webster, J., & Zedler, S. (2013). Estimating parameters in physical models through Bayesian inversion: A complete example. SIAM Review, 55(1), 149–167.