Here we build a Bayesian problem in which the forward model is a partial differential equation (PDE) model, the 1D heat problem in particular.
Try to at least run through part 1 to 4 before working on the optional exercises.
Table of contents¶
1.1. Learning objectives
1.2. Loading the PDE test problem
1.3. Building and solving the Bayesian inverse problem
1.4. Parametrizing the unknown parameters via step function expansion
1.5. ★ Observe on part of the domain
1.6. ★ Parametrizing the unknown parameters via KL expansion
1.1. Learning objectives ¶
Solve PDE-based Bayesian problem using CUQIpy.
Use different parametrizations of the Bayesian parameters (e.g. KL expansion, non-linear maps).
★ Indicates optional section.
This notebook was run on a local machine and not using github actions for this book due to its long execution time.
1.2. Loading the PDE test problem ¶
We first import the required python standard packages that we need:
import numpy as np
import matplotlib.pyplot as plt
from math import floor
import cuqi
# Disable progress bar dynamic update for cleaner output for the book. You can
# enable it again by setting it to True to monitor sampler progress.
cuqi.config.PROGRESS_BAR_DYNAMIC_UPDATE = FalseFrom CUQIpy we import the classes that we use in this exercise:
from cuqi.testproblem import Heat1D
from cuqi.distribution import Gaussian, JointDistribution
from cuqi.sampler import PCN, MH, CWMHWe load the test problem Heat1D which provides a one dimensional (1D) time-dependent heat model with zero boundary conditions. The model is discretized using finite differences.
The PDE is given by:
where is the temperature and is the thermal diffusivity (assumed to be 1 here). We assume the source term is zero. The unknown parameters (random variable) for this test problem is the initial heat profile .
The data is a random variable containing the temperature measurements everywhere in the domain at the final time corrupted by Gaussian noise:
where is the forward model that maps the initial condition to the final time solution via solving the 1D time-dependent heat problem. is the measurement noise.
Given observed data the task is to infer the initial heat profile .
Before we load the Heat1D problem, let us set the parameters: final time , number of finite difference nodes , and the length of the domain
N = 30 # Number of finite difference nodes
L = 1 # Length of the domain
tau_max = 0.02 # Final timeWe assume that the exact initial condition that we want to infer is a step function with three pieces. Here we use regular Python and NumPy functions to define the initial condition.
n_steps = 3
n_steps_values = [0,1,2]
myExactSolution = np.zeros(N)
start_idx=0
for i in range(n_steps):
end_idx = floor((i+1)*N/n_steps)
myExactSolution[start_idx:end_idx] = n_steps_values[i]
start_idx = end_idxWe plot the exact solution for each node :
plt.plot(myExactSolution)
plt.xlabel("i")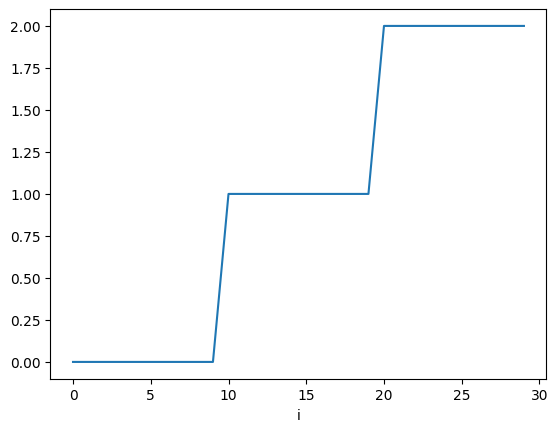
While it is possible to create a PDE model from scratch, for this notebook we use the Heat1D test problem that is already implemented in CUQIpy.
We may extract components of a Heat1D instance by calling the get_components method.
model, data, problemInfo = Heat1D(
dim=N,
endpoint=L,
max_time=tau_max,
exactSolution=myExactSolution
).get_components()Let us take a look at what we obtain from the test problem. We view the model:
modelCUQI PDEModel: Continuous1D[30] -> Continuous1D[30].
Forward parameters: ['x'].
PDE: TimeDependentLinearPDE.Note that the forward model parameter, named x here, is the unknown parameter which we want to infer. It represents the initial condition above, or a a parameterization of it.
We can look at the returned data:
dataCUQIarray: NumPy array wrapped with geometry.
---------------------------------------------
Geometry:
Continuous1D[30]
Parameters:
True
Array:
CUQIarray([0.04181817, 0.06347055, 0.12341149, 0.19324924, 0.19960263,
0.18010044, 0.32112614, 0.36708205, 0.44647237, 0.50078513,
0.61152796, 0.67085662, 0.76462026, 0.87778378, 0.8828829 ,
1.03861107, 1.08511243, 1.20793789, 1.19942345, 1.29700283,
1.30282151, 1.28141412, 1.26778429, 1.19996017, 1.07654557,
0.98457968, 0.77786535, 0.63530518, 0.43542921, 0.21921081])And the problemInfo:
problemInfoProblemInfo with the following set attributes:
['exactData', 'exactSolution', 'infoString']
infoString: Noise type: Additive i.i.d. noise with mean zero and signal to noise ratio: 200Now let us plot the exact solution (exact initial condition) of this inverse problem and the exact and noisy data (the final time solution before and after adding observation noise):
problemInfo.exactSolution.plot()
problemInfo.exactData.plot()
data.plot()
plt.legend(['exact solution', 'exact data', 'noisy data']);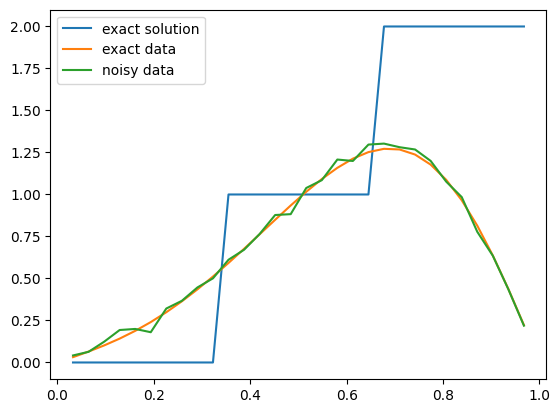
Note that the values of the initial solution and the data at 0 and are not included in this plot.
# Your code here
In case the parameters were changed in the exercise, we reset them here
N = 30 # Number of finite difference nodes
L = 1 # Length of the domain
tau_max = 0.02 # Final time
model, data, problemInfo = Heat1D(
dim=N,
endpoint=L,
max_time=tau_max,
exactSolution=myExactSolution
).get_components()1.3. Building and solving the Bayesian inverse problem ¶
The joint distribution of the data and the parameter (where represents the unknown values of the initial condition at the grid nodes in this section) is given by
Where is the prior pdf, is the data distribution pdf (likelihood). We start by defining the prior distribution :
mean = 0
std = 1.2
x = Gaussian(mean, cov=std**2, geometry=model.domain_geometry) # The prior distribution# Your code here
To define the data distribution , we first estimate the noise level. Because here we know the exact data, we can estimate the noise level as follows:
sigma_noise = np.std(problemInfo.exactData - data)*np.ones(model.range_dim) # noise levelAnd then define the data distribution :
y = Gaussian(mean=model(x), cov=sigma_noise**2, geometry=model.range_geometry)Now that we have all the components we need, we can create the joint distribution , from which the posterior distribution can be created by setting (we named the observed data as data in our code):
First, we define the joint distribution :
joint = JointDistribution(y, x)
print(joint)JointDistribution(
Equation:
p(y,x) = p(y|x)p(x)
Densities:
y ~ CUQI Gaussian. Conditioning variables ['x'].
x ~ CUQI Gaussian.
)
The posterior distribution pdf is given by the Bayes rule:
By setting in the joint distribution we obtain the posterior distribution:
posterior = joint(y=data)
print(posterior)Posterior(
Equation:
p(x|y) ∝ L(x|y)p(x)
Densities:
y ~ CUQI Gaussian Likelihood function. Parameters ['x'].
x ~ CUQI Gaussian.
)
We can now sample the posterior. Let’s try the preconditioned Crank-Nicolson (pCN) sampler (~40 seconds):
MySampler = PCN(posterior, scale=0.01)
MySampler.warmup(10000, tune_freq=0.01)
MySampler.sample(20000)
posterior_samples = MySampler.get_samples()Warmup: 100%|██████████| 10000/10000 [00:19<00:00, 504.61it/s, acc rate: 48.62%]
Sample: 100%|██████████| 20000/20000 [00:40<00:00, 492.30it/s, acc rate: 41.89%]
Note here we use the warmup sampling method for the entire sampling run and we set the tuning frequency to 0.01, which means that the scale of the proposal distribution is adapted every 1% of the samples.
Let’s look at the credible interval:
posterior_samples.plot_ci(95, exact=problemInfo.exactSolution)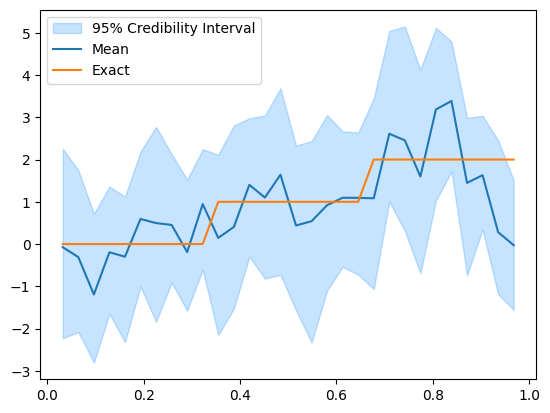
We can see that the mean reconstruction of the initial solution matches the general trend of the exact solution to some extent but it does not capture the piece-wise constant nature of the exact solution.
Also we note that since the heat problem has zero boundary conditions, the initial solution reconstruction tend to go to zero at the right boundary.
1.4. Parametrizing the unknown parameters via step function expansion ¶
One way to improve the solution of this Bayesian problem is to use better prior information. Here we assume the prior is a step function with three pieces (which is exactly how we created the exact solution). This also makes the Bayesian inverse problem simpler because now we only have three unknown parameters to infer.
To test this case we pass field_type='Step' to the constructor of Heat1D, which creates a StepExpansion domain geometry for the model during initializing the Heat1D test problem. It is also possible to change the domain geometry manually after initializing the test problem, but we will not do that here.
The parameter field_params is a dictionary that is used to pass keyword arguments that the underlying domain field geometry accepts. For example StepExpansion has a keyword argument n_steps and thus we can set field_params={'n_steps': 3}.
n_steps = 3 # number of steps in the step expansion domain geometry
N = 30
model, data, problemInfo = Heat1D(
dim=N,
endpoint=L,
max_time=tau_max,
field_type="Step",
field_params={"n_steps": n_steps},
exactSolution=myExactSolution,
).get_components()
Let’s look at the model in this case:
modelCUQI PDEModel: StepExpansion[3: 30] -> Continuous1D[30].
Forward parameters: ['x'].
PDE: TimeDependentLinearPDE.We then continue to create the Bayesian inverse problem (prior, data distribution and then posterior) with a prior of dimension = n_steps.
# Prior
x = Gaussian(mean, std**2, geometry=model.domain_geometry)
# Data distribution
sigma_noise = np.std(problemInfo.exactData - data)*np.ones(model.range_dim) # noise level
y = Gaussian(mean=model(x), cov=sigma_noise**2, geometry=model.range_geometry)And the posterior:
joint = JointDistribution(y, x)
posterior = joint(y=data)We then sample the posterior using Metropolis Hastings MH sampler (~40 seconds)
MySampler = MH(posterior, scale=0.01)
MySampler.warmup(10000, tune_freq=0.01)
MySampler.sample(20000)
posterior_samples = MySampler.get_samples()Warmup: 100%|██████████| 10000/10000 [00:15<00:00, 635.26it/s, acc rate: 25.61%]
Sample: 100%|██████████| 20000/20000 [00:41<00:00, 484.78it/s, acc rate: 23.00%]
Let’s take a look at the posterior:
posterior_samples.plot_ci(95, exact=problemInfo.exactSolution)
posterior_samples.shape(3, 30000)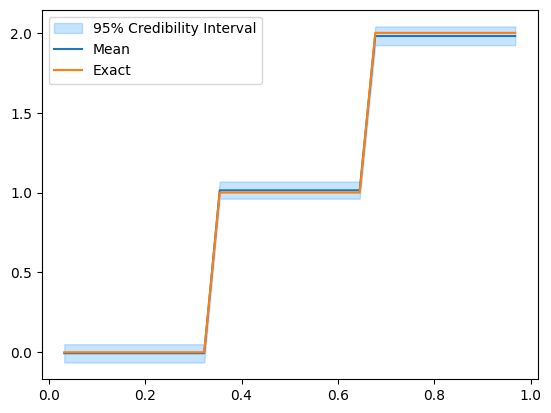
We show the trace plot: a plot of the kernel density estimator (left) and chains (right) of the n_steps variables:
posterior_samples.plot_trace()array([[<Axes: title={'center': 'x0'}>, <Axes: title={'center': 'x0'}>],
[<Axes: title={'center': 'x1'}>, <Axes: title={'center': 'x1'}>],
[<Axes: title={'center': 'x2'}>, <Axes: title={'center': 'x2'}>]],
dtype=object)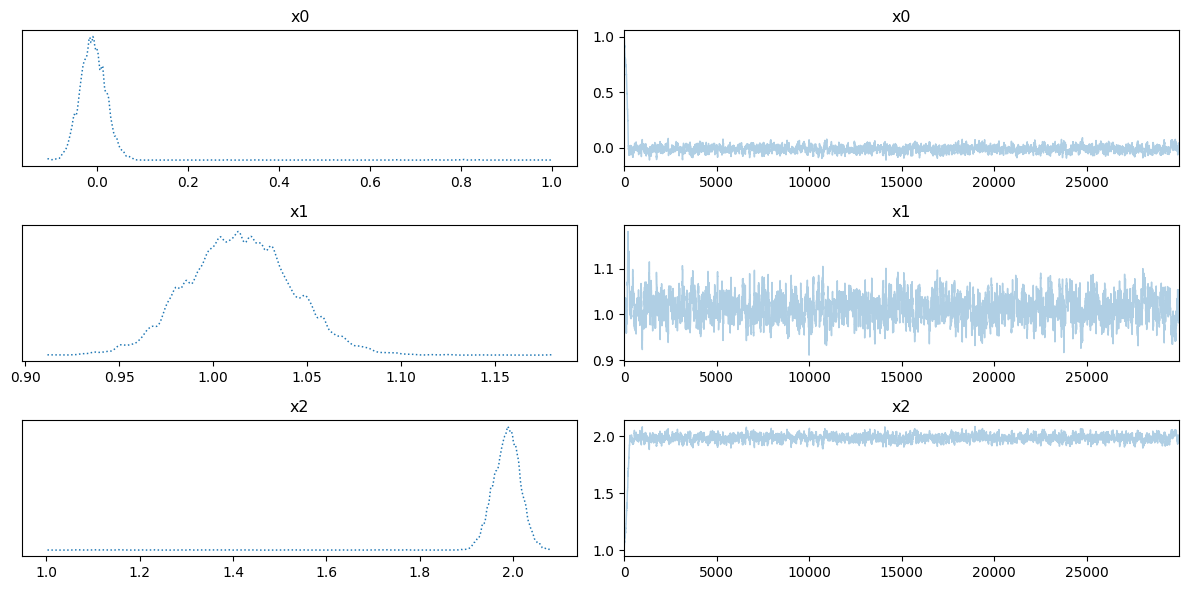
We show pair plot of 2D marginal posterior distributions:
posterior_samples.plot_pair()array([[<Axes: ylabel='x1'>, <Axes: >],
[<Axes: xlabel='x0', ylabel='x2'>, <Axes: xlabel='x1'>]],
dtype=object)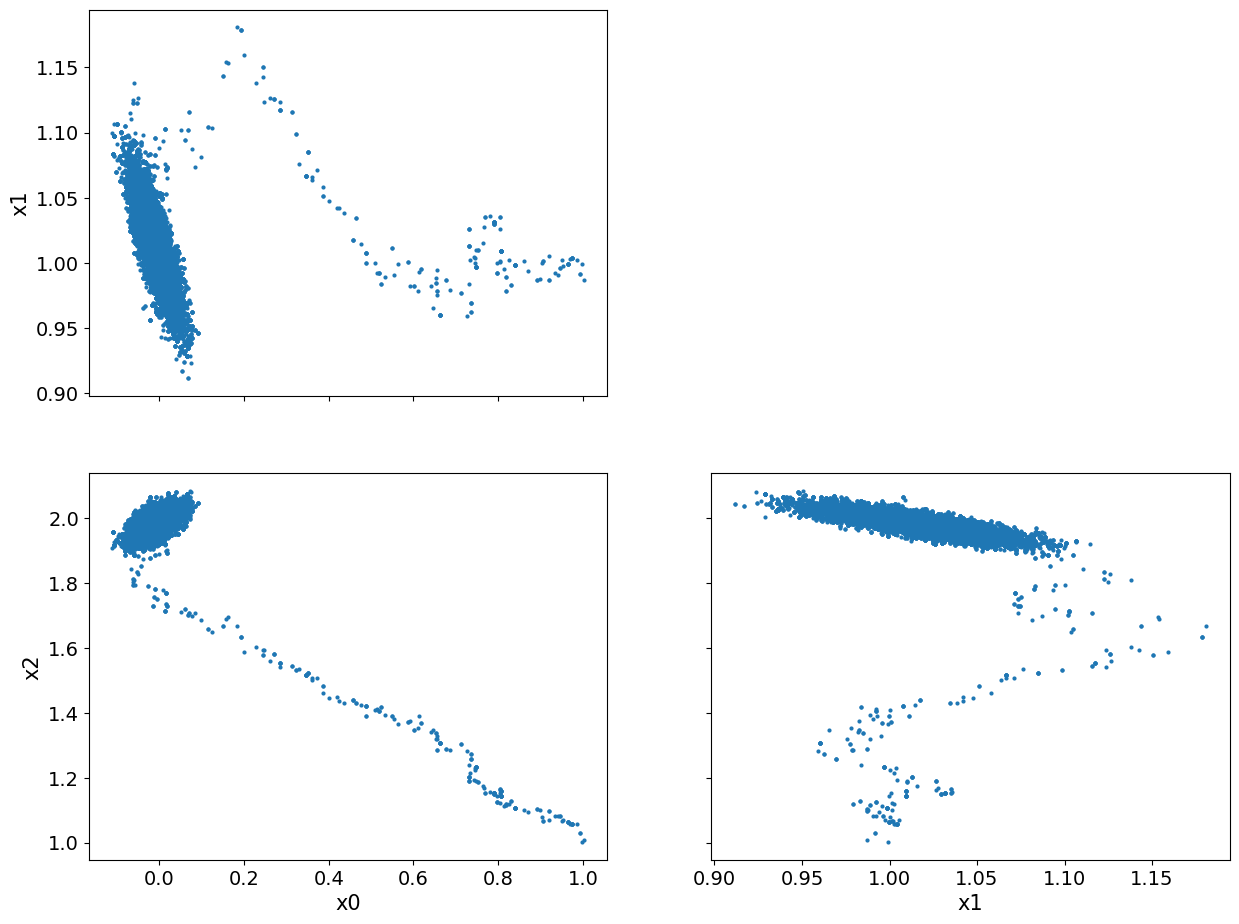
We notice that there seems to be some burn-in samples until the chain reaches the high density region. We show the pair plot after removing 1000 burn-in:
posterior_samples.burnthin(1000).plot_pair()array([[<Axes: ylabel='x1'>, <Axes: >],
[<Axes: xlabel='x0', ylabel='x2'>, <Axes: xlabel='x1'>]],
dtype=object)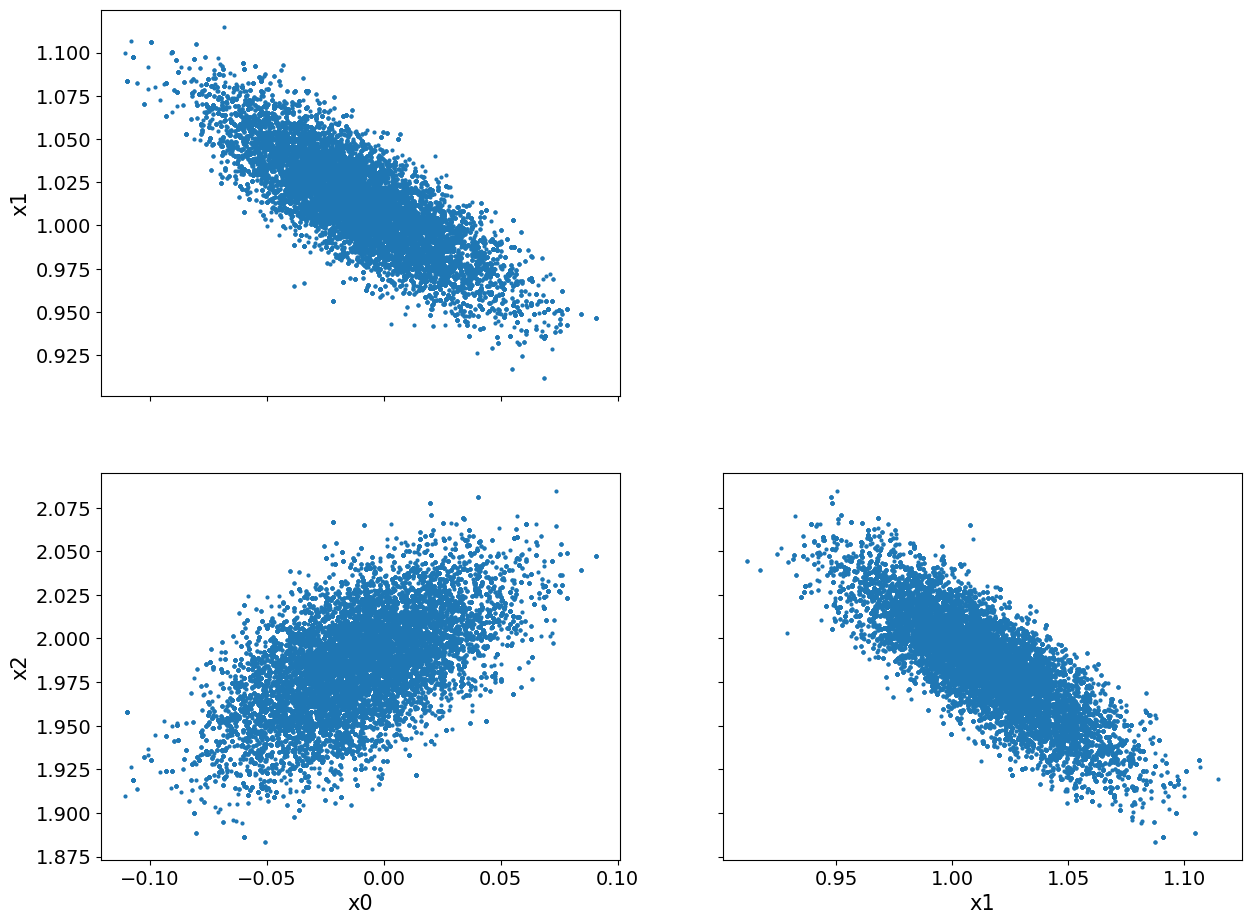
We can see that, visually, the burn-in is indeed removed. Another observation here is the clear correlation (or inverse correlation) between each pair of the variables.
We can also see the effect of removing the burn-in if we look at the credible interval before and after removing the burn-in. Let us look at the credible interval before:
posterior_samples.plot_ci(100, exact=problemInfo.exactSolution)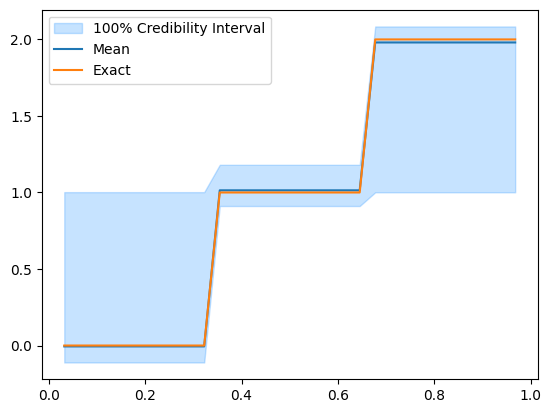
And after removing the burn-in:
posterior_samples.burnthin(1000).plot_ci(100, exact=problemInfo.exactSolution)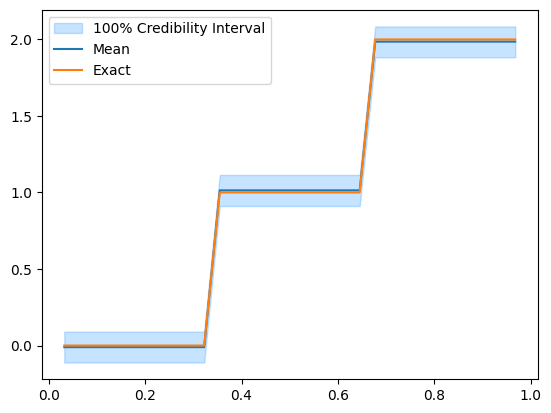
We compute the effective sample size (ESS) which approximately gives the number of independent samples in the chain:
posterior_samples.compute_ess()array([669.33576244, 695.19711267, 572.16526158])# Your code here
1.5. ★ Observe on part of the domain ¶
Here we solve the same problem as in section 3 but with observing the data only on the right half of the domain.
We chose the number of steps to be 4:
N = 30
n_steps = 4 # Number of steps in the StepExpansion geometry. Then we write the observation_nodes map which can be passed to the Heat1D.
It is a lambda function that takes the forward model range grid (range_grid) as an input and generates a sub grid of the nodes where we have observations (data).
# observe in the right half of the domain
observation_nodes = lambda range_grid: range_grid[np.where(range_grid>L/2)] We load the Heat1D problem. Note in this case we do not pass an exactSolution. If no exactSolution is passed, the Heat1D test problem will create an exact solution.
model, data, problemInfo = Heat1D(
dim=N,
endpoint=L,
max_time=tau_max,
field_type="Step",
field_params={"n_steps": n_steps},
observation_grid_map=observation_nodes,
).get_components()
Now let us plot the exact solution of this inverse problem and the exact and noisy data:
problemInfo.exactSolution.plot()
problemInfo.exactData.plot()
data.plot()
plt.legend(['exact solution', 'exact data', 'noisy data']);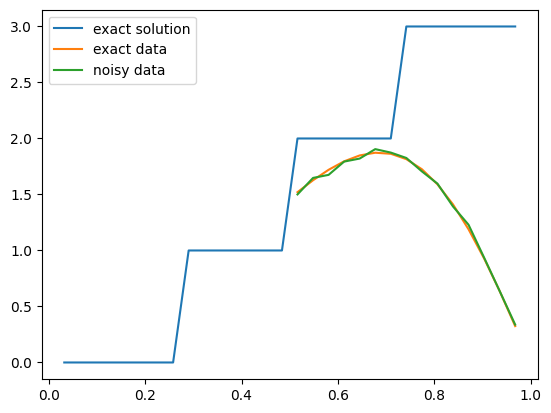
We then continue to create the Bayesian inverse problem (prior, data distribution and then posterior) with a prior of dimension = 4.
# Prior
x = Gaussian(1, std**2, geometry=model.domain_geometry)
# Data distribution
sigma_noise = np.std(problemInfo.exactData - data)*np.ones(model.range_dim) # noise level
y = Gaussian(mean=model(x), cov=sigma_noise**2, geometry=model.range_geometry)And the posterior:
joint = JointDistribution(y, x)
posterior = joint(y=data)We then sample the posterior using the Metropolis Hastings sampler (~50 seconds)
MySampler = MH(posterior, initial_point=np.ones(posterior.dim), scale=0.01)
MySampler.warmup(10000, tune_freq=0.01)
MySampler.sample(20000)
posterior_samples = MySampler.get_samples()Warmup: 100%|██████████| 10000/10000 [00:19<00:00, 506.86it/s, acc rate: 27.46%]
Sample: 100%|██████████| 20000/20000 [00:46<00:00, 430.68it/s, acc rate: 23.91%]
Let’s take a look at the posterior:
posterior_samples.burnthin(1000).plot_ci(95, exact=problemInfo.exactSolution)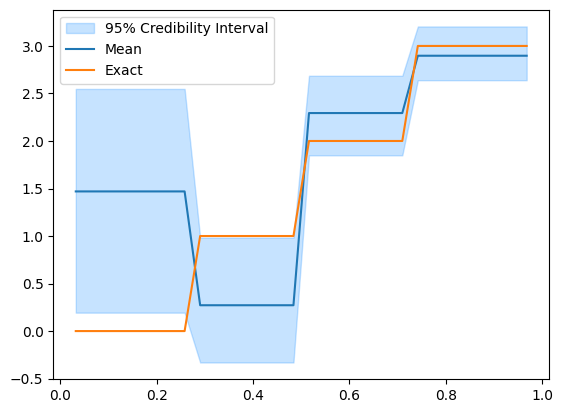
We see that the credible interval is wider on the side of the domain where data is not available (the left side) and narrower as we get to the right side of the domain.
1.6. ★ Parametrizing the unknown parameters via KL expansion ¶
Here we explore the Bayesian inversion for a more general exact solution. We parametrize the Bayesian parameters using Karhunen–Loève (KL) expansion. This will represent the inferred heat initial profile as a linear combination of sine functions.
where is the grid point (in a regular grid), , is the number of nodes in the grid, is a decay rate, is a normalization constant, and are the expansion coefficients (the Bayesian parameters here).
Let’s load the Heat1D test case and pass field_type = 'KL', which behind the scenes will set the domain geometry of the model to be a KL expansion geometry (See KLExpansion documentation for details):
N = 35
model, data, problemInfo = Heat1D(
dim=N,
endpoint=L,
max_time=tau_max,
field_type="KL"
).get_components()
Now we inspect the model:
modelCUQI PDEModel: KLExpansion[35] -> Continuous1D[35].
Forward parameters: ['x'].
PDE: TimeDependentLinearPDE.And the exact solution and the data:
problemInfo.exactSolution.plot()
problemInfo.exactData.plot()
data.plot()
plt.legend(['exact solution', 'exact data', 'noisy data']);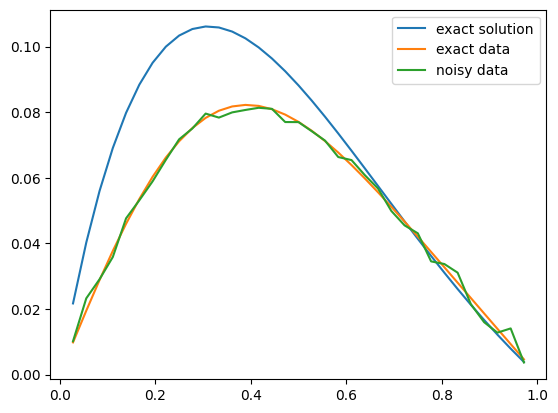
Note that the exact solution here is a general signal that is not constructed from the basis functions. We define the prior as an i.i.d multivariate Gaussian with variance 32. We determined the choice of this variance value through trial and error approach to get a reasonable Bayesian reconstruction of the exact solution:
sigma_prior = 3*np.ones(model.domain_dim)
x = Gaussian(mean, sigma_prior**2, geometry=model.domain_geometry)We define the data distribution:
sigma_noise = np.std(problemInfo.exactData - data)*np.ones(model.range_dim) # noise level
y = Gaussian(mean=model(x), cov=sigma_noise**2, geometry=model.range_geometry)And the posterior distribution:
joint = JointDistribution(y, x)
posterior = joint(y=data)We sample the posterior, here we use Component-wise Metropolis Hastings (~70 seconds):
MySampler = CWMH(posterior, initial_point=np.ones(N))
MySampler.warmup(500, tune_freq=0.01)
MySampler.sample(1000)
posterior_samples = MySampler.get_samples()Warmup: 100%|██████████| 500/500 [00:22<00:00, 21.94it/s, acc rate: 83.50%]
Sample: 100%|██████████| 1000/1000 [00:41<00:00, 23.81it/s, acc rate: 84.09%]
And plot the credibility interval (you can try plotting different credibility intervals, e.g. )
posterior_samples.plot_ci(95, exact=problemInfo.exactSolution)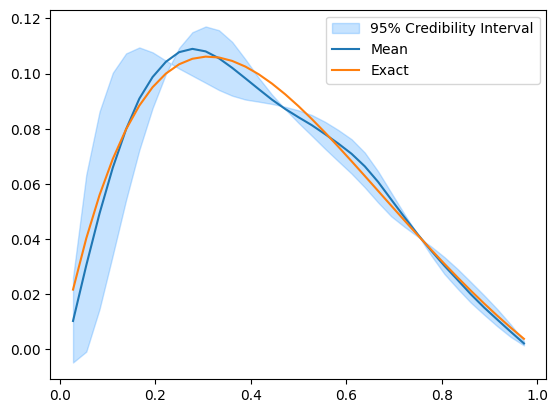
The credibility interval can have zero width at some locations where the upper and lower limits seem to intersect and switch order (uppers becomes lower and vice versa). To look into what actually happen here, we plot some samples:
posterior_samples_burnthin = posterior_samples.burnthin(0,10)
for i, s in enumerate(posterior_samples_burnthin):
model.domain_geometry.plot(s)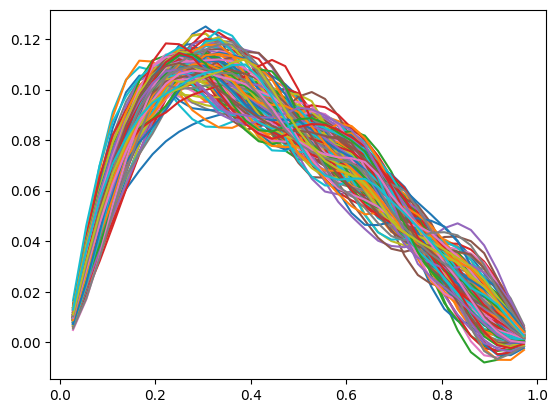
The samples seem to paint a different picture than what the credibility interval plot shows. Note that the computed credibility interval above, is computed on the domain geometry parameter space, then converted to the function space for plotting. We can alternatively convert the samples to function values first, then compute and plot the credibility interval.
Convert samples to function values:
funvals_samples = posterior_samples.funvalsThen plot the credibility interval computed from the function values:
funvals_samples.plot_ci(95, exact=problemInfo.exactSolution)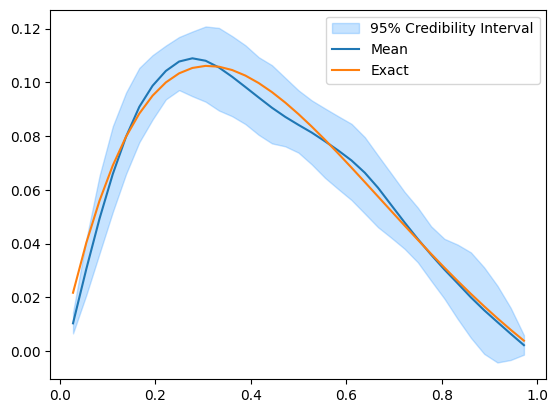
We can see that the credibility interval now reflects what the samples plot shows and does not have these locations where the upper and lower bounds intersect.
Let’s look at the effective sample size (ESS):
posterior_samples.compute_ess()array([ 13.89498309, 86.59526051, 33.4952966 , 35.22909807,
19.64747056, 40.78028797, 27.59884532, 6.48730459,
42.1034294 , 34.67819842, 39.21678355, 53.68098792,
232.89145852, 24.84105971, 47.81815365, 27.59056769,
40.98615845, 52.42587981, 33.0851814 , 30.19984195,
40.5420712 , 32.80385525, 46.15750952, 31.00501381,
72.43179575, 42.92200579, 40.18656054, 44.59902073,
52.86549743, 58.07077628, 33.90572235, 36.15875918,
39.97440483, 3.81942191, 29.80511209])We note that the ESS varies considerably among the variables. We can view the trace plot for, let’s say, the first and the second variables:
posterior_samples.plot_trace([0,1])array([[<Axes: title={'center': 'x0'}>, <Axes: title={'center': 'x0'}>],
[<Axes: title={'center': 'x1'}>, <Axes: title={'center': 'x1'}>]],
dtype=object)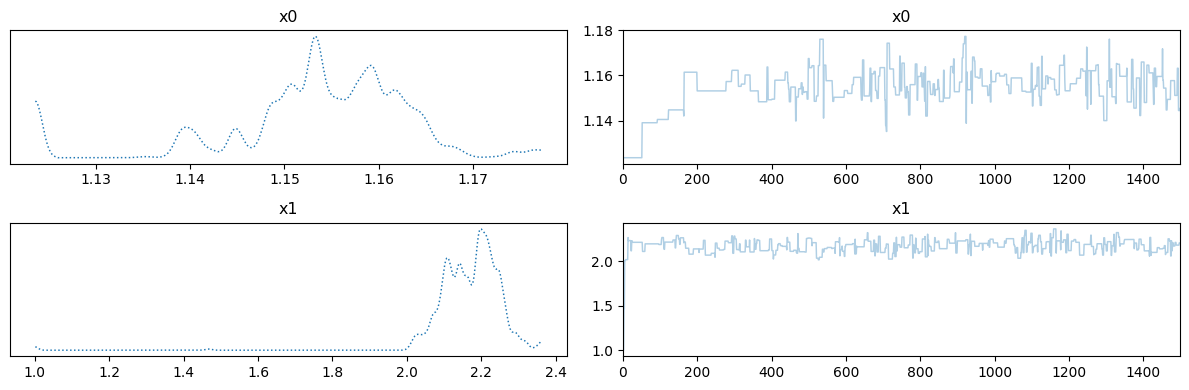
We note that the (as expected from the values of ESS) the chain quality of , which corresponds to the second coefficient in the KL expansion, is much better than that of the first variable . Low quality chain (where chain samples are highly correlated) indicates difficulty in exploring the corresponding parameter and possibly high sensitivity of the model to that particular parameter. Sampling methods that incorporate gradient information (which we do not explore in this notebook) are expected to work better in this situation.
A third way of looking at the credibility intervals, is to look at the expansion coefficients credibility intervals. We plot the credibility intervals for these coefficients from both prior and posterior samples by passing the flag plot_par=True to plot_ci function:
The prior:
plt.figure()
x.sample(1000).plot_ci(95, plot_par=True)
plt.xticks(np.arange(x.dim)[::5]);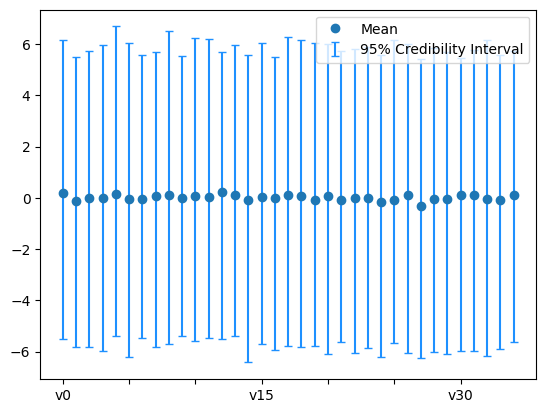
The posterior:
posterior_samples.plot_ci(95, plot_par=True)
plt.xticks(np.arange(x.dim)[::5]);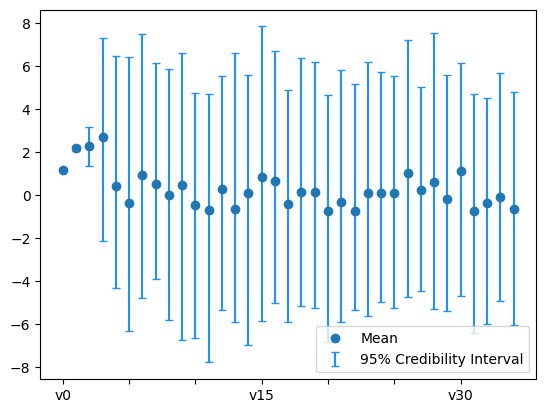
By comparing the two plots above, we see that the first few coefficients are inferred with higher certainty than the remaining coefficients. In parts, this is due to the nature of the Heat problem where high oscillatory initial heat features (corresponding to the higher modes in the expansion) will be smoothed out (lost) faster and thus are harder to retrieve based on measurements from the final solution.